
How to Read a Deep Learning Paper
(With a TLDR at the top)

TLDR:
Abstract first, always.
The final paragraphs of the intro next. Often it's just an extended abstract.
Look for the architecture figure and get a sense of how information is flowing through the model. There's often a "core insight" about how information ought to move that defines the model.
Look at the matrix math and manually "follow" how an input vector is transformed. If this still doesn't ‘click’, draw it out as matrices. Try to understand what transforms different matrices are applying. Worst case, look at the code directly, run it and modify it to get a sense of what's happening.
Once you've got the insight, try and understand the larger "conversation". Look at the related work section. See if you can answer questions like "why might this paper be important?" and "what is it responding to?". Look for other papers that are answering similar questions.
Ignore the experimental results. Most of them are cherry picked.
Long version.
Theory means a lot of different things in deep learning. To me, theory is "everything that can be predicted on a whiteboard". Newtonian mechanics is theory. Evolution is theory. Genetics is theory.
Deep learning is a field without theory. Don't get me wrong, there are important innovations in ML theory, like the universal approximation theorem or PAC learning. But deep learning itself is basically a mystery. There isn't a single person on the planet who can say with certainty how fundamental changes in things like data distribution, sampling distribution, model architecture, or loss function will impact the output Still, many people have intuition about what deep ml models are doing; everyone is wrong; some intuition is more useful than others. Deep learned models get better. And papers get published. So so many papers.
Unfortunately, we live in an era where "good science" requires theory. In fact, theory is paramount. Papers in every other discipline start and end with theory. You can’t just publish a paper being like “this is what I observed”, it would never get published. This makes the act of writing a deep learning paper rather challenging. Deep learning is, at its core, all intuition.
In my experience, in order to get published, many deep learning papers will wrap their core insight around layers of obfuscating "theory". Papers will draw comparisons to mathematical equivalences or biological analogies in order to seem more rigorous. (Luckily this has become less of an issue in the last few years — possibly because more and more AI shops are exclusively publishing to arxiv or their own sites — but it still happens more often than I'd like.) As a result, when reading a deep learning paper, you have to get really good at filtering out the bullshit that may just be there for journal reviewers.
The best way to filter out noise is to always be on the hunt for the core insight that the authors had when writing the paper. A good paper (good means interpretable, not necessarily impactful!) clearly signals where the insight comes from. The original Transformer paper, Attention is All You Need, is a great example of this. The "query, key, value" terminology is directly coming from databases, and vector databases in particular use a very similar matmul to find "relevant" data.
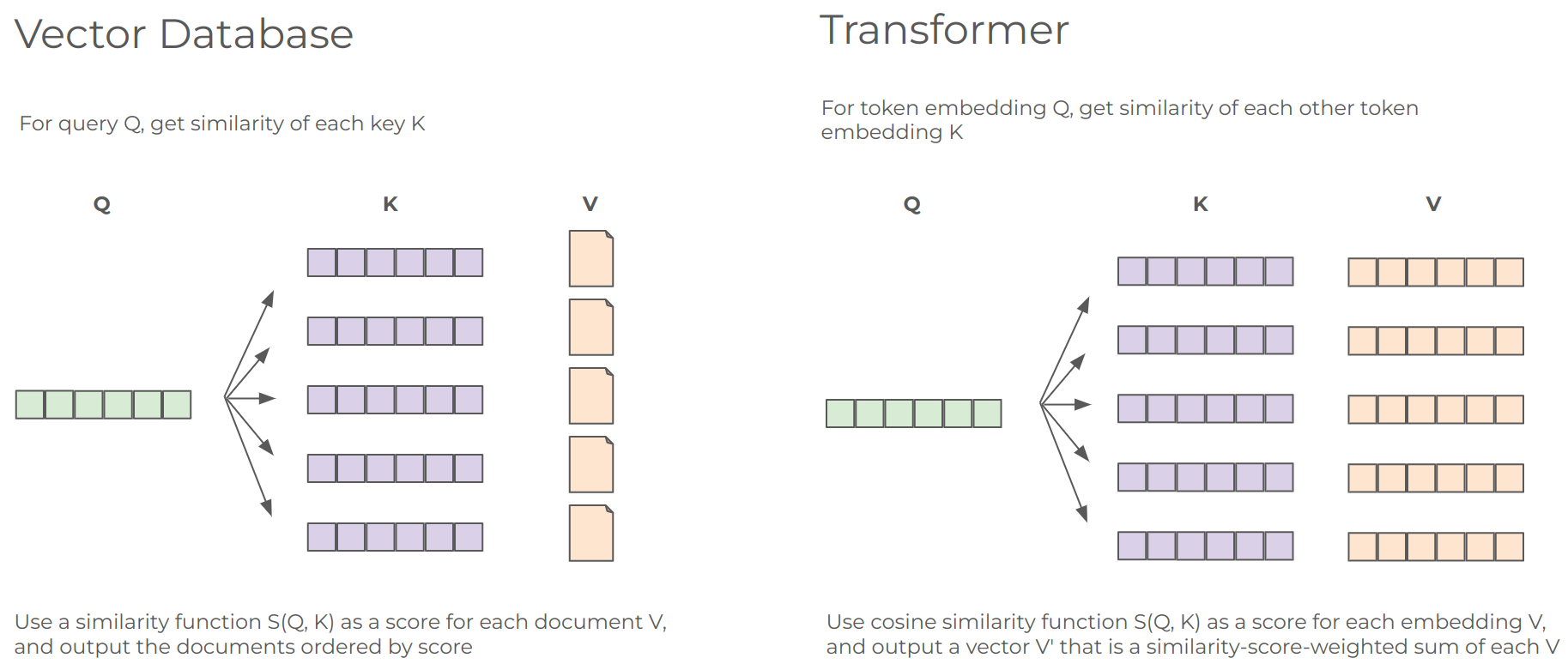
The original Graph Convolutional Network paper, on the other hand, leaves a lot to be desired — there's words and words about approximating Chebyshev polynomials and spectral graph theory that, in the end, boils down to "you can use the graph adjacency matrix to pool neighborhoods of data into a node".

Looking for insight is tough, especially because what makes sense to you may not make sense to other people. It took me a long time for the QKV terminology of transformers to really click. It wasn't until I was independently playing with FAISS for SOOT that I really got it. Still, there's a few tricks you can use.
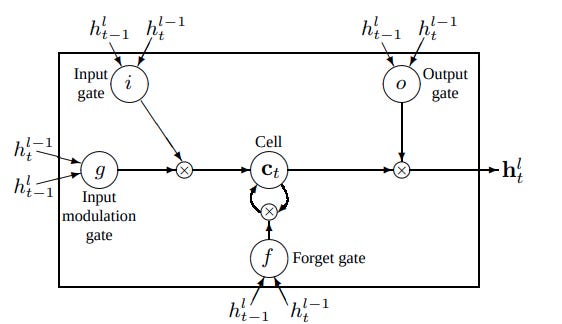
I always start by looking for an "architecture image". Many (most?) deep learning papers have one. This is a figure, generally the biggest one, generally on page 2 or 3, that describes the feed forward pass of the model and highlights how information moves around. Try to understand what layers "represent". What operations are being performed? For example, if you're reading up on LSTMs, try and independently figure out what role different weights in the LSTM might play based on how they impact the output of the model. If you squint, you might be able to identify that one set of weights determines how much historical data to keep, while another determines how much new data to "write" into memory.
If there is no architecture image, or if the image isn't super helpful, look for a set of equations that define the model and scan the paper for a description of those equations. These equations are often written with matrix notation. Each matrix has a 'purpose' in the model — try and figure out what that purpose is. What might the matrix look like after training? After a matrix multiplication, what is the output? What information might the output represent? Don't be afraid to draw out the matrix multiplications so that you really understand what each dimension of the matrix represents. A good example of where this may be useful is the Attention Free Transformer paper. This paper proposes adding an additional square weight matrix of size sequence length into the standard transformer attention block. By looking at the equations, and in particular thinking about the shapes of the matrices, you can figure out that the additional weights represent a "fixed" attention map instead of the usual attention map that is a function of the input sequence tokens.
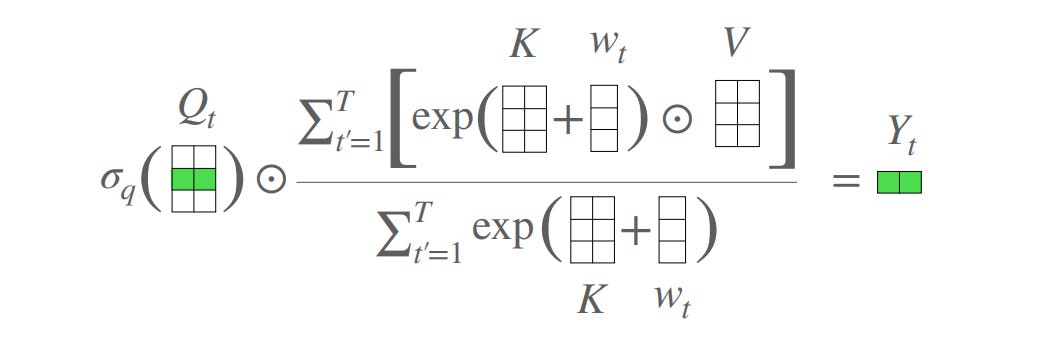
Sometimes I still don't really feel like I have a great grasp of a paper. I've stared at the figures, tried to make sense of the equations, and still nothing. In that scenario, I'll go look at GitHub and find an implementation, ideally one that includes a description of what's going on. Take a look at the Annotated Transformer, or relevant blog posts by folks like Karpathy for the gold standard. Sometimes just looking at the torch code will spark that necessary leap of logic to figure out what a paper is trying to say. Luckily there's a huge open community of researchers and enthusiasts, so there's tons of blogs talking about all the major papers. Go join a discord and ask some questions, everyone is friendly.
Once I've understood the core insight of the paper, I'll go back over it with an eye towards understanding it's "place in the conversation". Why does this paper exist? What problem is it trying to solve, or what paper is it in response to? What other papers add context to this one? Recently, Yoshua Bengio published a paper titled "Were RNNs all we needed?" It made some waves in part because, in isolation, it's strange that one of the luminaries of deep learning is writing about RNNs in 2024. But in context, it's clear that Bengio is responding to a long chain of papers that are all dealing with the limitations of the sequential nature of RNNs against the quadratic complexity of Transformers. This is a conversation that has been going on for at least a decade.
From here, I generally feel like I've got everything I can from the paper itself. Papers often take on a life of their own so it can be worth keeping an eye on how papers land in the larger community. The most influential papers create a lot of conversation, so don't feel anxious if you can't keep up with the volume (it's more noise than signal anyway).
One thing to add: ignore the experimental results.
Every paper needs to have a section that shows the paper does what it says. It's a requirement for publication. And as a result, every paper will always be "the best" along some axis — generally one of training speed, inference speed, memory usage, or output quality. The problem is that it's near impossible to determine whether the results are cherry picked. (They often are, even for good models!) And it's so so common to hear about a promising model that blows away benchmarks, only to discover that in practical settings no one can replicate the magic claimed in the paper.
My advice is to just save your time. Don't bother reading the experimental results unless you're trying to replicate the paper or publish a response. You'll figure out if the model is any good by paying attention to the community. If people are excited, if they keep adding new implementations and improvements, if the model results in spin off work, it probably works! And if not, well, understanding the experimental results isn't going to change that.
Now that I'm no longer at SOOT, I'm hoping to start a series of posts that's grounded in core insights behind papers that I think are cool. Stay tuned!