


Ilya's 30 Papers to Carmack: RNNs
Did you mean: recursion?

This post is part of a series of paper reviews, covering the ~30 papers Ilya Sutskever sent to John Carmack to learn about AI. To see the rest of the reviews, go here.
Paper 2: The Unreasonable Effectiveness of Recurrent Neural Networks
High Level
I always enjoy reading posts from Karpathy. Yes, of course, he's an excellent ML engineer, and his writing is filled with unique insights that push the entire field forward in leaps and bounds. But he is also just so obviously excited about neural networks. He loves these things. He's fascinated by how they work — that they even work at all! — and can't help but share his wonder with the world. I mean this in the best possible way: he writes with the authenticity of a child discovering something about the world for the first time. That authenticity is infectious, it bubbles through in every word that he writes, and makes me more excited about neural networks too.
The Unreasonable Efficacy of RNNs isn't really a paper. I mean, literally it's a blog post. But also, it does not set out to prove something new or beat some benchmark. Rather, it's closer to a tutorial or a survey, a nice little bow on top of years of prior work. Which is why I figured the best time to review this post was after we had gotten through most of the other papers on Sutskever's list. We discussed RNNs in our review of LSTMs, Set2Set, ResNets, Attention, Relational Networks (both times), and Neural Turing Machines. Here, we're going to talk about why everyone was seemingly obsessed with these things, such that they made up the backbone of so many of these other papers. Before we really dive in, I recommend just reading the blog post. It is extremely approachable. Then, if you're still interested, skip down to the insights section below.
Why do we care about RNNs? Recurrent neural networks have an interesting property that many other types of neural nets don't have: they operate on sequences. An MLP or a conv net can be quite powerful, but they are limited to learning maps. You take some input and produce some output, and that's it. These neural networks can't dynamically allocate additional compute. They can't operate over arbitrary sized inputs. Their "API is too constrained."
By contrast, RNNs are significantly more flexible. Because they operate on sequences, they have the ability to run indefinitely, ingesting arbitrary state and producing arbitrary outputs. And RNNs can be used for things that ConvNets or MLPs are used for too — you can always operate on a sequence of length one, or take some input and split it up into smaller chunks. Sequences are a strictly more general class of data structure, and there's a lot of reason to believe that anything approaching Artificial General Intelligence will have to be, well, general.

Now, just as a note on terminology, you can absolutely have convolutional layers inside an RNN. In fact, you can have any kind of neural network structure in an RNN. LSTMs are a mix of matmuls and learned weights; Recurrent Relational Networks stick an entire self attention block in there. Unlike other model architectures that are defined primarily by their usage of particular layers (MLPs, ConvNets, Transformers) the main thing that makes an RNN an RNN is the recurrence. An RNN takes its previous state (or all of its previous states) as input, and uses that to inform its output and the next hidden state.

Traditional, non-recurrent neural nets approximate functions. RNNs approximate programs. Because they take in their previous state, RNNs can in theory do all sorts of things, like pass information between timesteps, predict further into the future than the current timestep, and develop individualized 'stages' of processing over time. RNNs are known to be Turing complete — they can theoretically stimulate any program that a normal computer can run.
Here's an example program. Let's say you wanted to train a character generator: given some text, the model should predict the next most likely character in a sequence. Just to keep things simple, we're only going to look at 4 characters, 'h', 'e', 'l', 'o', and we're going to try to get the model to output "hello". Even though we only have one word, we actually have 4 separate training samples at the character level.
Given the letter 'h', the model should predict 'e'
Given the letters 'he' the model should predict 'l'
Given the letters 'hel' the model should predict 'l'
And given the letters 'hell' the model should predict 'o'
Because we are training a per-character generator, any amount of text can be broken down this way. You can get millions of samples from a single blog post!
Now, of course, neural nets don't natively understand letters. All of this needs to be turned into vectors. So you take each character and one-hot encode it, which in turn lets you represent any input sequence with your characters as a matrix.

Each element of the sequence gets processed sequentially. The model outputs a probability distribution for each character given all of the previous characters in the sequence. We use backprop to make sure the model's predictions align with the actual output. For example, when the model has "he" as an input, we want to make sure that the model puts a high prediction on the character 'l'. In our little example vocabulary, that translates to producing a vector that is as close to [ 0, 0, 1, 0 ] as possible. We update the weights based on the delta between the actual prediction and the desired prediction.
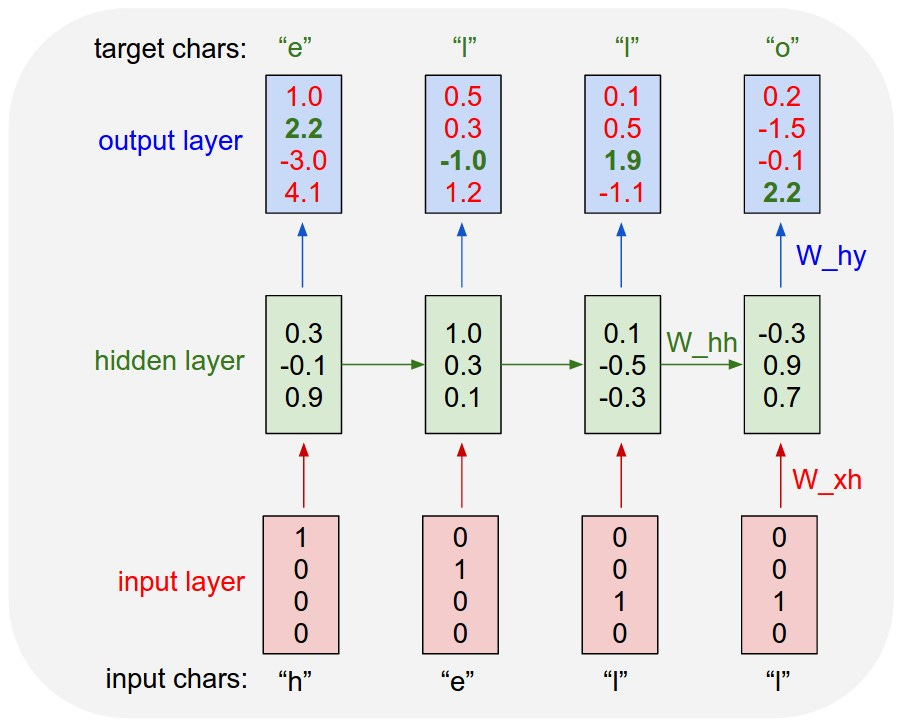
After each step of backprop, we'll find that the model is more likely to predict the right characters (e.g. instead of -1.0 it may jump up to -0.8, then -0.5, and so on). Eventually, assuming everything goes well, the model will 'converge' — the updates will be small, and the model will have approximated the probability of the letter 'l' following "he" according to the frequency of that pattern in the input training set.
You may wonder why we go through all of this. If the goal is to just predict the likelihood that the letter 'l' follows the letters "he", couldn't you figure that out directly by analyzing the training data? Count up all of the times an "he" appears, count up all of the times an 'l' appears after it, divide, and boom — you have your probability. In fact, this is more or less what Markov models do. The problem of course is that randomly sampling the probability distribution of two-letter-conditioned characters is going to give you gibberish. It's just not enough context. You need the probability of 'l' given all prior data, not just the previous two letters. The beauty of an RNN is not that it can tell you the exact probability an 'l' follows the characters "he". Rather, the beauty comes from the fact that the RNN can correctly tell you that the first time it sees an 'l', the next output ought be an 'l'; and the second time it sees an 'l', the next output ought be an 'o'. In other words, the RNN is compressing the character statistics of all character probabilities in one model, over a theoretically infinite context window.
In the described setting, RNNs have a unique property: they spit out the same type of thing as what they take in. RNNs ingest strings of characters, and spit out strings of characters. That means that once you have a trained model, you can take whatever the model produces and feed it back in to get more. This is called "auto-regressive modeling" — auto, or "self", and regressive, or "going back"; together, using your own previous output.
You can run an RNN trained this way forever. It will keep spitting out new characters based on what came before, following whatever patterns it learns from the trained set. So if you train it on, say, Paul Graham essays, you get this:
The surprised in investors weren’t going to raise money. I’m not the company with the time there are all interesting quickly, don’t have to get off the same programmers. There’s a super-angel round fundraising, why do you can do. If you have a different physical investment are become in people who reduced in a startup with the way to argument the acquirer could see them just that you’re also the founders will part of users’ affords that and an alternation to the idea. [2] Don’t work at first member to see the way kids will seem in advance of a bad successful startup. And if you have to act the big company too.
And if you train it on Shakespeare, you'll get this:
PANDARUS: Alas, I think he shall be come approached and the day
When little srain would be attain'd into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.DUKE VINCENTIO:
Well, your wit is in the care of side and that.Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I'll have the heart of the wars.Clown:
Come, sir, I will make did behold your worship.VIOLA:
I'll drink it."
These are obviously not quite baked, especially in the context of 2025 LLMs. But there's clearly something here. These models are extremely simple — the largest model Karpathy trains is a basic 3-layer LSTM with only 10M parameters — but they are capable of creating near legible text.
If you try Wikipedia, or latex, or code, you get all sorts of interesting results. The model seems capable of opening and closing parenthesis. It hallucinates variables and names and URLs. It more or less memorizes the GNU license. You can even roughly "prompt" these models in a rudimentary way, by starting to write some text manually and then having the model fill in the rest (more or less exactly what people were doing with GPT-2 and GPT-3).
One neat thing about an auto-regressive generative model is that you can poke and prod at it to get a window into what it learns.
During training we want to ensure that the model is stable and does not go off the rails. Obviously you want to watch the loss, and it is very easy to create graphs where the loss decreases over time. But it's also common to have these models output some text at each checkpoint, so we can see roughly what that checkpoint corresponds to and whether the decrease in loss corresponds to good results. As a nice side effect, you get a neat qualitative measure of model performance — you can track what the model tends to pick up first, and then how it builds on those foundations.
Karpathy runs an experiment with an LSTM trained on War and Peace, and notes the following:
At step 100, the model mostly gives you random characters separated by uneven numbers of spaces
tyntd-iafhatawiaoihrdemot lytdws e ,tfti, astai f ogoh eoase rrranbyne 'nhthnee e plia tklrgd t o idoe ns,smtt h ne etie h,hregtrs nigtike,aoaenns lng
At step 300, the spacing thing is basically solved. You start seeing quotation and punctuation appearing, along with dynamic 'sentence lengths'.
"Tmont thithey" fomesscerliund Keushey. Thom here sheulke, anmerenith ol sivh I lalterthend Bleipile shuwy fil on aseterlome coaniogennc Phe lism thond hon at. MeiDimorotion in ther thize."
At step 500, the punctuation is sorted out, and the model has moved on to trying to produce semi-coherent words (as an aside, this is probably how Adriano Celentano writes music).
we counter. He stutn co des. His stanted out one ofler that concossions and was to gearang reay Jotrets and with fre colt otf paitt thin wall. Which das stimn
At 700, the words are more obviously English.
Aftair fall unsuch that the hall for Prince Velzonski's that me of her hearly, and behs to so arwage fiving were to it beloge, pavu say falling misfort how, and Gogition is so overelical and ofter.
At 1200, all of the words are definitely English, and the model starts producing structures that look more grammatically correct.
"Kite vouch!" he repeated by her door. "But I would be done and quarts, feeling, then, son is people...."
And by step 2000, we basically have a "coherent" text generator (at least, in the Chomsky sense).
"Why do what that day," replied Natasha, and wishing to himself the fact the princess, Princess Mary was easier, fed in had oftened him. Pierre aking his soul came to the packs and drove up his father-in-law women.
There's a pretty clear structure in the order things are learned. Remember, the model starts with soup — it doesn't know fundamentals like 'spaces are used to separate words', much less something complicated like 'the grammatical structure of English'. As things coalesce from the soup, we observe the model picking up foundational patterns first, before moving on to things that are more specific to the text at hand.
I don't have the space to formally explain why this occurs, but it seems intuitive to me. In theory you could imagine a world where the model learns how to separate words with spaces last. Like, at step 1200, it's spitting out text like "thequickbrownfoxjumpedoverthelazydog" and only at step 2000 does it figure out how to separate those words with spaces. But in practice that would never happen. The model learns more foundational things first because there are more examples of those things in any given sentence. A space separates a word 8 times in the sentence "the quick brown fox jumped over the lazy dog." By contrast, the next most frequent characters are 'e' and 'o' which both appear only 4 times, each time in very different contexts. The model is trying to reduce its prediction loss; of course it learns spaces first! That's where it gets the most bang for its buck.
What else can we tease out from these models?
Remember that the model is not trained to generate text, per se. Rather, it is trained to predict the next most likely character. Or, more precisely, to predict a probability distribution of the next most likely character, over all characters. If we feed the model some input text we can visualize the model's output distribution for each character in the input text and potentially learn something about what patterns the model picked up during training.
Here's one such visualization.

There's a lot going on here, so let's break it down bit by bit.
The first row — the text outside of any grid — is the input. In this case, it is a chunk of a URL at the beginning, along with the first few words of the description of the URL. The full text is
ttp://www.ynetnews.com/] English-language website of Israel's larFor every character, we see the top five most likely next characters laid out in a column underneath it, colored by how confident the model is in the prediction. The darker the color, the more confident. So for example, in this section of the text:

The model starts by strongly predicting that the letter 'f' will follow the letter 'o' (making the word 'of') and then correctly adds a space. Then, it thinks the next character will be 't' (perhaps to start the word 'the', as in 'of the'). The next character is instead an 'I', so it weakly but correctly predicts an 's'. And then afterwards, the model guesses an 'l', likely to make the word 'Island'. When instead the character afterwards is an 'r', the model confidently finishes out the rest of the word 'Israel' (though it guesses the word "Israelis" instead of the word "Israel's".
One pattern should immediately pop out: the model becomes significantly more confident as you get to the end of each word. In the example above, the model is very unsure what will follow the spacebar. It could be any word. "Website of" is not much of a prefix; and even if you were looking at the full input sequence, the model would have to somehow know what ynetnews is in order to directly guess Israel. So as a result, the model puts equal weight on a few characters — 's', 'n', 'r'. But once you get the 'I-s-r', the model becomes super confident that 'a-e-l' will follow.
The same thing happens with 'English-language':

So even though the model is only 'thinking' in characters, it clearly has 'words' somewhere in its underlying representation.
By the same token (pun intended), the model is most 'confused' after a space. This makes sense to me — the next word after a space could be anything. We see the same uncertainty after the '.' in the URL:

The model is very confident about "www.", but literally anything could follow that '.' character! So the model has more or less equal guesses on a lot of characters — we only see 'b', 'a', 's', 'n', and 'd' as the top 5, but I suspect the model is equally uncertain across the entire character vocabulary.
Earlier I mentioned that the model has 'words' somewhere in the underlying representation, even though it outputs characters. In this case, the representation we care about is the vector hidden state that is passed along at each step of the model. This vector is a highly compressed store of data, containing information about all of the previous characters as well as all of the biases the model picked up during training. We can observe how different dimensions in this vector light up by seeing, character by character, whether a given dimension has a large value or a small value.
Ideally, every dimension in this vector corresponds to a single specific real world human understandable concept. For example, you could have a dimension for 'happiness'. The value in the index for that dimension gets really large when the model talks about 'happy' things. Of course, this isn't how these models work — you can't have a single dimension for every possible concept. There's too many things! So instead, the model learns a really entangled representation, where each dimension relates to every other dimension in some extremely complicated way.1
But sometimes we do get really interpretable dimensions. Here's a two examples.

The first example shows a cell that has really small values at the beginning of a line, and larger values as the model gets closer to the end of a line. In other words, it looks like it tracks line position.
The second example shows a cell that has really small values outside of quoted segments, and really large values when inside quoted segments. In other words, it looks like it tracks quoted characters.
In both cases, it is pretty obvious why a model would want to track these properties. The model likely conditions the next most likely character based on heuristics like ‘where are we in a sentence’. But the model isn't hard coded to learn any of these things. We give the model a high level task — "predict the next character" — and during training the model develops the capability to track whether it is inside a quote or not. This is an "emergent" behavior. One thing that's hard about deep learning is that it's extremely difficult to predict what kind of emergent behaviors a model picks up in the process of solving other tasks. But this is also the magic of deep learning. The model gradually tuned a cell to figure out quote detection, because that helped the final result.
Karpathy ends his blog post with, among other things, a review of where he thinks the field is going. In 2015, the most exciting area of research is attention. No one really knows how exactly attention will play out, but virtually everyone is convinced that attention is going to be part of the next big thing. To really emphasize the point, Karpathy puts this in a big pull quote separated from the rest of the text for added impact:
The concept of attention is the most interesting recent architectural innovation in neural networks.
RNNs have two big problems.
First, RNNs aren't that good at inductive reasoning — that is, they don't seem to generalize well based on small samples of data. They can memorize sequences, but there are noted issues with getting an RNN to learn broader structure outside of the sequence. Ironically this is likely due to a very strong inductive bias: RNNs are by default very locally sensitive, and so cannot readily generalize across long sequences.
Second, it's obvious existing RNNs are limited by their hidden state size, which is unnecessarily tied to compute. By default, doubling the hidden state requires quadrupling the number of FLOPs. So ideally we want to be able to increase the amount of context a model could potentially access at each step without having to massively increase the hidden state.
Attention mechanisms potentially address both. You can use attention to 'attend' to specific vectors over otherwise extremely large memory banks without increasing your per-step cost, either by learning a probability distribution over your stored vectors ("soft" attention) or by discretely selecting parts of a memory bank using non-differentiable RL learning ("hard" attention). Even though we don't use them much today, in 2015 the Neural Turing Machine was an obvious example of how attention could meaningfully improve deep neural nets. NTMs had longer context windows than basically any RNN that came before it, basically just because of its attention mechanism.
Karpathy also spends some time in his conclusion discussing papers, people, and engineering considerations. I won't go into much depth here; much of these no longer apply. But it's fascinating to skim through from a historical/archeological perspective of what people were thinking about a decade prior.
Insights
Of course, in 2025, it's obvious that Karpathy's intuition was basically entirely correct. Attention wasn't just important, it turned out to be all we needed (badum ts).
More generally, the first time I read this post I was rather shocked how prescient it all seemed — or maybe, how much of the techniques and architectures and methods of today are really just scaled up versions of the same things people were doing in 2015. Karpathy talks about hallucinations and temperature and auto regressive generation. He talks about token counts and dataset sizes and compute scaling. He talks about polysemanticity (in layman's terms) and basic interpretability techniques. If you swapped out RNNs with transformers, it would be identical to something that would do the rounds on HN today. On the one hand, this implies that the old masters really were ahead of the curve. On the other, it means there's still a lot of ground to do new things. Self-attention and transformers is an outgrowth of research that started in 2014, a result of the entire industry pushing on this-one-cool-thing-that-we-know-is-important-but-not-sure-how. We don't yet have clarity on what that next big swing is.
Whatever it is, it needs to be easy to train. One of the things that stuck out to me about this post was a brief aside Karpathy makes at the beginning.
Sometimes the ratio of how simple your model is to the quality of the results you get out of it blows past your expectations, and this was one of those times. What made this result so shocking at the time was that the common wisdom was that RNNs were supposed to be difficult to train (with more experience I’ve in fact reached the opposite conclusion). Fast forward about a year: I’m training RNNs all the time and I’ve witnessed their power and robustness many times, and yet their magical outputs still find ways of amusing me.
I've trained several RNNs in my time, mostly seq2seq models for language translation, and I always thought they were a pain in the ass. They never really seemed to do the right thing, and they were far more inscrutable than conv nets. That "common wisdom" was there for a reason. But Karpathy is right that RNNs are extremely easy to train when you use them for auto regressive modeling.
I think as researchers we sometimes underestimate how important ease of training actually is. When GANs came onto the scene, lots of people made a big deal about their theoretical properties — they were solving some kind of game-theoretic Nash equilibrium that was blah blah blah. The real reason GANs became popular was because you could get decent results on small problems without actually doing all that much besides collecting a dataset. They were actually pretty easy to train for things like MNIST. In interviews, Goodfellow talks about how he got his first GAN working in less than an hour, basically on his first try, once he had the idea. But GANs ended up being discarded, even though you could get really good results out of them, because it turned out that their training regimes were stupidly complicated if you wanted to do anything at any kind of scale.
By contrast, next token prediction is an incredible training regime. Every sentence is self-labeled, so you don't have to spend any time or resources going through each line to filter noise. The unit of training is a single token, which means even straightforward easily scraped paragraphs can represent thousands of training samples. You get pretty clean gradients throughout the training process because your actual output is a classification. The model architecture is likewise very straightforward when it comes to IO. And solving the actual task is obviously "AI hard" — for an AI to perfectly handle next token prediction, it needs to understand higher level concepts, abstract over long contexts, and continue learning about how semantics shift over time. In retrospect, it feels obvious that any exploration of auto-regressive text modelling was going to be a winner.
That's not to say that Karpathy's excitement about RNNs specifically is misplaced. Rather, in 2015, virtually all of the auto regressive work being done was using RNNs, and there was a lot of reason to believe that auto regressive learning was extremely powerful, and RNNs were the natural way to explore that training regime.
And if you broaden your aperture around what an RNN actually is, you see them everywhere. Even though there is a well understood “basic” RNN architecture, the family of RNNs include things like LSTMs or GRUs. And like I said earlier, you can stick a convolutional network in an RNN if you wanted. In my view, an RNN is less a particular architecture and more a type of ‘meta’ model frame. Instead of tackling a task in a single shot, you design your model to learn a set of sub-problems that, together, solve the overall task. This is why, in my review of the ResNet paper, I argue that ResNets are essentially just RNNs.

The defining characteristic of a ResNet is that the 'residual stream' allows the model to share 'hidden state' between layers, break up tasks into smaller chunks, and tune / optimize those chunks separately. That's basically what an RNN is! I think one could argue that because ResNets use different weights at each step, they aren't truly 'recurrent'; the 'recurrent' in recurrent neural network requires weight sharing across steps. But you could easily imagine a ResNet that does share weights, or alternatively, an LSTM that learns a bunch of different functions at different parts of the sequence.
From this broader perspective, many different models behave like RNNs. For example, even though transformers are generally considered to be a 'different' model, they also use residuals, which means they share hidden state and learn subtasks across each layer.

And though I haven't yet written a review for diffusion models yet, I think that they behave like a nested RNN — diffusion models often have residuals within the model, and also each step of the diffusion process 'outside' of the model can be thought of as a step in a RNN sequence with shared weights.
So two big takeaways for me.
The ease of the next-character-prediction task — and later, the next-token-prediction task — is perhaps the critical thing, and I can't help but feel like it will continue to play a role as we continue to generalize what a 'token' is.
RNNs are here to stay, and we will continue to see the general usefulness of their 'meta' architecture.
Speaking of that latter point, what is the state of RNNs today, in 2025? Not in the "all residual networks are actually RNNs" sense, but in the common-usage models-that-have-recurrent-patterns sense?
Even though transformers have completely dominated the industry over the last 6-7 years, they are not without issues. The big problem is that transformer compute scales quadratically with sequence length; each additional token in your context window requires tons more compute. This is why all the big AI labs are shelling out literal billions of dollars to buy chips. RNNs don't have this problem. RNN compute scales linearly with sequence length; each additional token gets the same amount of compute as all previous tokens.
As transformers have gotten larger, a few researchers have turned back to RNNs to see if there are ways to retrofit them for the modern AI world. The last big paper I saw in this direction was "Were RNNs all we needed?", a paper that came out near the end of 2024 by Bengio's lab. More recently, a cool demo of a neural operating system was making the rounds, which used an RNN as part of its state tracking. Other than that, though, it's been mostly crickets.
I suspect we won't really ever see the mass adoption of RNNs in their original form as a key driver of frontier models. Even though they have nice scaling properties, most of the time we actually want the extra parameters. A mentor of mine, currently at OAI, actually believes that we need to increase the amount of compute per token — he's always talking about cubic attention models! But there are a lot of lessons we can take from sequential modeling, and I think we will be toying with recurrent-like models for years and years to come.
The technical term for this is the 'linear representation hypothesis', which is related to ‘polysemanticity’ and ‘superposition’. We'll talk more about this when we get around to reviewing the Anthropic "Toy Models of Superposition" paper.