

Tech Things: NYT sues OpenAI, OpenAI bans ByteDance, and Tesla Charging Plugs
Tech Things: NYT sues OpenAI, OpenAI bans ByteDance, and Tesla Charging Plugs

NYT sues Open AI
I was so tempted to title this "Tiny $8B struggling news agency sues massive $80B tech behemoth" but that felt a bit too tongue in cheek.
Very broadly speaking, OpenAI is in the business of selling access to a large neural network that, given a sequence of text, can predict what the next most likely string of text should be.
Roughly, you have this blob of matrix multiplications that all start out with random values. You also have a bunch of real-world sentences that you pull from a bunch of different sources. You convert each token in the sentence to a number, so that the sentences become lists of numbers. And then you hide some values and ask the system to predict what values were hidden.
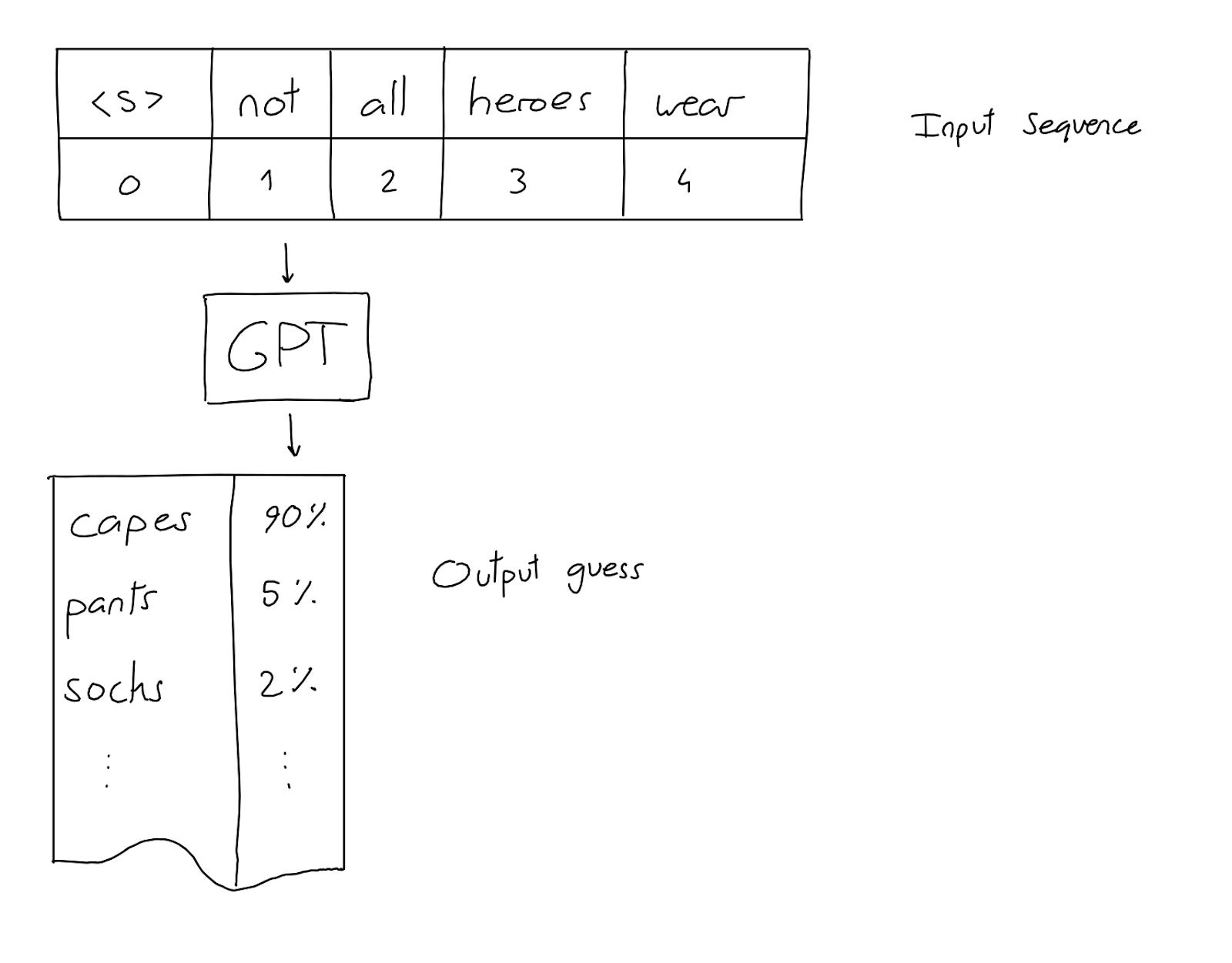
The first few times, the model will predict nonsense. The matrix multiplication that you're doing is just random values! But each time you pass data through the system, you adjust those matrix weights so that next time the model produces something more accurate.
There are a lot of open theoretical questions on how these neural networks actually work, and what the right 'metaphor' is to reason about the behaviors of these things.
The simplest, worst way to think about a neural network is that it's a complicated database. The model somehow stores all of the data it learns from in a complete form, and then mixes and matches that data like a collage to produce new outputs. Yes there's training and there's inference and some magic words about GPUs and normalization and so on, but at the end of the day you give this blob of CS some documents, and it spits out those documents. So it's a database.
A smart person might say, 'hey wait a sec, the data that went in is terabytes of data, much larger than the final model size, so surely it's not a database!' And this is true. So a slightly-more-nuanced but still-bad way to think about a neural network is that it's a database with a very bad data compression system. The output model can sorta recreate the inputs, kinda like how a low res camera can sorta recreate a high-definition image.
I take a more philosophical approach to all of this. If you give infinite monkeys infinite typewriters, one of them will eventually produce the collected works of Shakespeare. That means that the words already existed, somewhere in the abstract ether; Shakespeare was simply the first person to discover them. In my mind, a neural network is a way of organizing the ether. You give it a bunch of text documents, and it "learns" an internal representation of the shape of all possible words.
I've written about this before, about images:
Every image that has ever existed, or ever will exist, can be found in a 'library' that contains every combination of pixel values of a certain height and width. Most of the images are total noise, like polar bears in a blizzard. But every photograph, every wood-carving, every postmodern whatever image lives there too.
Humans use our considerable brain power to traverse this RGB terrain of images, pulling out aesthetically pleasing works that have significance. And we use tools that help us — search engines to help us find inspiration, image editors to sharpen our lines or fill in colors, algorithms to fill in content. Not so long ago artists had to mix their own paints.
The same thing is true of text. In my opinion, there is no obvious bright-line between auto-complete on a phone and auto-complete with a neural network.
Is that how the NYT sees it? What the fuck do you think, lmao???
The NYT is in the business of selling words the old way — by paying someone to write them. OpenAI is in the business of selling words the new way — that is, with cheap automated computation. And the latter is worth something like 10x the former. So even if the NYT agreed with every word I just said about how AI is just a tool to further human expression, that's not what they are going to say in court!
From the court filing:
75. At the heart of Defendants’ GenAI products is a computer program called a “large language model,” or “LLM.” The different versions of GPT are examples of LLMs. An LLM works by predicting words that are likely to follow a given string of text based on the potentially billions of examples used to train it.
80. Models trained in this way are known to exhibit a behavior called “memorization.” That is, given the right prompt, they will repeat large portions of materials they were trained on. This phenomenon shows that LLM parameters encode retrievable copies of many of those training works.
98. As further evidence of being trained using unauthorized copies of Times Works, the GPT LLMs themselves have “memorized” copies of many of those same works encoded into their parameters. As shown below and in Exhibit J, the current GPT-4 LLM will output near-verbatim copies of significant portions of Times Works when prompted to do so. Such memorized examples constitute unauthorized copies or derivative works of the Times Works used to train the model.
Look, I really don't have any deep love for the NYT. But I have to admit, this is not a good look for OpenAI or for LLMs.
No one is denying that OpenAI used the NYT articles. Hell, no one is even denying whether or not LLMs will be able to perfectly output training text — they obviously do, and in fact that's working as intended! The central question of the case is whether or not OpenAI's use of NYT is fair-use. From Bloomberg:
The case will ultimately hinge on copyright law’s fair use doctrine, attorneys said. The legal test asks courts to evaluate four factors to determine whether an unauthorized copy is legal: the “transformativeness” of the copying; the nature of the copyrighted work; the amount of work copied; and the market harm from the copying.
The complaint has evidence that could favor the Times on the fourth factor, which examines market harm.
By making copied Times articles available for free, the newspaper said, OpenAI and Microsoft’s copying threatens its subscription revenue.It's obvious to me that OpenAI is doing something transformative from a technical perspective. But good luck convincing a judge and jury. The folks over at the Times just have to show slide after slide of near-verbatim copies of their work. And yea, the OpenAI lawyers can sputter and complain about how this is just a very small sample of all of the possible outputs, or about chinese robbers, or whatever. But show anyone 100 examples of obvious copyright infringement, and it starts to look like the whole thing is just copyright infringement. I think it'll be very easy (not a lawyer!) to convince a judge that these LLMs are just a fancy database.
And to be honest…the NYT may have a point? You can use LLMs to do an end-run around NYT paywalls. While that isn't the primary use case for something like ChatGPT, it clearly is a use case.
The biggest issue for OpenAI is that you can't ever fully separate LLM "memorization" from learning. Even if the LLM didn't take any NYT articles during training, it could theoretically output NYT articles anyway! Infinite monkeys with infinite typewriters, that's the model working as intended! The Library of Babel contains every piece of text, copyright be damned. So if the NYT wins this case we can expect massive lawsuits against all of the other players, even if they weren't relying on scraped data.
But just because the law says something is illegal doesn't mean it's unethical. Maybe it's also time for a new way of thinking about and adjudicating data rights. Back in the early 90s, the courts ruled that copying data from a hard drive to RAM was a copyright violation. Your computer copies data from the hard drive to RAM literally all the time, to do anything at all, so this ruling was tantamount to banning computers. And in fact, this ruling was so obviously stupid that Congress got off it's ass for once and actually changed the law to fix this obvious fuckery. Maybe we should do the same thing here?
More likely, though, AGI will come and eat us all long before the legal system updates to account for this brave new world.
Open AI bans Bytedance
In order to create a large language model, you need a lot of text. That text needs to be real, in some sense. You can easily string together a bunch of random words in a sequence, but that's not going to help you create an ML model that can generate coherent English sentences. One way to get a lot of text is to scour the annals of human thought, i.e. download as much of the internet as possible and do some data cleaning. Luckily there are big databases of web data available, including Wikipedia, Reddit, and, yes, the NYT archives.
But it takes a lot of time and energy to scrape a bunch of text and clean it up for use during ML training. And it's also questionably legal (see above). And it seems like OpenAI already has this service that produces a bunch of coherent text…couldn't we just generate text from OpenAI and use that to train different models?
Actually yes! You can 100% do that, this is a well known field in AI called synthetic data generation. And OpenAI knows that you can do that, and, I kid you not, explicitly states that scraping OpenAI models for training data is a violation of ToS. So, in a bit of sweet irony, right before the NYT sued OpenAI, OpenAI banned Bytedance's account from using ChatGPT for using GPT to train its own models. From The Verge:
TikTok’s entrancing “For You” feed made its parent company, ByteDance, an AI leader on the world stage. But that same company is now so behind in the generative AI race that it has been secretly using OpenAI’s technology to develop its own competing large language model, or LLM.
This practice is generally considered a faux pas in the AI world. It’s also in direct violation of OpenAI’s terms of service, which state that its model output can’t be used “to develop any artificial intelligence models that compete with our products and services.” Microsoft, which ByteDance is buying its OpenAI access through, has the same policy. Nevertheless, internal ByteDance documents shared with me confirm that the OpenAI API has been relied on to develop its foundational LLM, codenamed Project Seed, during nearly every phase of development, including for training and evaluating the model. I think this is called "pulling the ladder up from underneath you". Last I checked, OpenAI was very happy to hoover up tons of scraped data that wasn't theirs. It's a bit rich that they would turn around and ban folks for doing the same thing to them.
Also, like, I'm not sure why The Verge is saying that it's a "faux pas" to train on GPT. It's pretty common knowledge that approximately everyone is using GPT to generate training data. A few friends of mine work on AI detection and report that a single AI detector generalizes to GPT, Claude, Llama, Stability… which is reasonably good evidence that they're all using the same corpus of data to train on or, more likely, fine tuning with GPT generated data. The only model out there that isn't using GPT to train is Google's Bard. Which, you know, makes sense — Google doesn't need GPT to get high quality data.
Everyone's using Tesla's charging plugs

This year my New Year's Resolution is to be more grateful, and I'm going to start by expressing my gratitude to people who write, maintain, and create 'standards'. The concept of a standard is actually pretty simple. It's a bunch of people getting together and agreeing to use the same interface, so that everyone can benefit. HTTP is a standard — that's why every web browser can access (almost) every website. The metric system is a standard. Electricity outlets, voltages, and amps are all set to a standard — this is why you need to bring adapters for different countries that aren't on the same standard. Every screw, bolt, drill bit that you've ever used or seen has a complex set of standards that dictate their manufacture.
And the result is that we can take a screw from one Ikea bed frame and apply it to some Amazon shelf with a completely independent screwdriver and everything just works. As you can imagine, standards are really fucking important, especially in STEM disciplines.
It's important to realize that this is not the default state of nature; standards bodies are, in a very real sense, a mark of civilization. Imagine a world where you had to remember to bring a different outlet adapter every time you drove from NYC to NJ. Or where you had to drive your Volkswagon to Volkswagon-branded gas stations, because your Volkswagon had a unique gas port that's different from, say, Chevy. That would suck, right?
Every now and then, a bunch of people invent some new technology. Like electric vehicles. And in the early days, there aren't any standards. So if you have a fully electric Mercedes, and you want to charge it at work, but your work only has Tesla chargers…well, get fucked, I guess. For a really long time, one of Tesla's main selling points was that you could charge your car in a lot of places. Cars need energy to move, and they move around to lots of places, so this was actually a pretty big deal!
But eventually the industry standardizes. The USG announced a $7.5B support package for a network of fast EV chargers that could support multiple EV brands across the country, and soon after Tesla announced its intention to make their ports standard. For Christmas in 2023, Tesla got its wish. On Dec 18th, SAE International — an important standards organization for a wide variety of engineering disciplines, including automotives — got together and published a formal standardization for the Tesla Supercharger, now named the North American Charging Standard. And the next day, VW joined all of the other major car companies in adopting the standard for its new cars.
I live in NYC and hope to never have to buy a car. But now, if I ever wanted to by an EV, I know that I could charge it wherever I wanted! Praise the standards bodies!