
A Primer on How to Deploy LLMs: Part 2

[This is Part 2 of a series. See Part 1, Part 3.]
Improving Results with Context Retrieval
Abstractly, any problem solving requires two things: 'reasoning' and 'data'. You need both to solve a problem — you need the data to get to the right answer, and you need reasoning to know what to do with the data. LLMs are the same. You can give the LLM more data to work with. And you can make the LLM bigger to make it smarter.
Since we are black boxing the actual LLM for the purposes of this document, we're going to assume that the latter is out of reach and focus on how we can give the LLM the right data. I call this process 'context retrieval' — we are retrieving the necessary context for the LLM to make the correct decision.
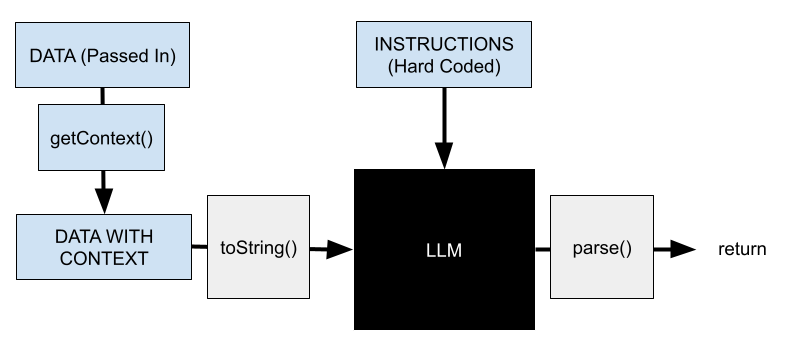
In some sense, there isn't really a difference between DATA and DATA WITH CONTEXT, at least from the eyes of the actual LLM. The LLM itself only sees string data after all. But I think this is a useful additional abstraction because there are a ton of ways to do context retrieval, up to and including asking another LLM. You can nest these sorts of requests pretty deep! In my opinion, most of the meat of deploying LLMs comes in crafting how to get the right context for the model.
A lot of getContext calls will be straightforward database lookups that can be hardcoded. For example, if you have an LLM customer support agent, it may make sense to include in your input all of the previous messages that a person sent to the agent. That's an easy SQL query that can be hard coded at the start of each conversation, and doesn't require anything fancy beyond appending strings together (this is basically how all chat completion works).
The more interesting problems lie in fuzzy lookups that are highly context dependent. For example, maybe a user wants to know the price of an item on Amazon from your general purpose LLM customer support agent. You probably don't have that data present in your database, nor would you have known to hard code a query like that. In these cases, you have to do something else…
Using LLMs to call External Tools
…like use LLMs to call external tools.
This is actually a bit of a misnomer. The LLM doesn't call the external tool directly. Rather, you prompt the LLM with a set of API definitions — function names, parameter descriptions, basically anything you might write in a docstring — and ask the LLM to output what function it thinks it should call, with what possible parameters.
For the example above, I might provide the following input:

And the model might output something like getAmazonContext('BLAH'). But note that this is still a string! I have to then turn this into code that I can actually run to hit the amazon endpoint.
Generally, this is done not by outputting an actual function, but rather by having the LLM output a parameter that can then be fed into a switch statement. For example, instead of outputting getAmazonContext('BLAH'), I might ask it to output something like AMAZON BLAH, and then switch on the first word, feed in the second as a parameter.
A more visual depiction of the same process, from OpenAI:

Again, note that it is explicitly on your application to actually call out to any third party services.
Overall, this now creates a 2-LLM system. The first LLM is used to generate the context that is then fed into the second LLM to solve some actual underlying problem.

I want to pause for a minute and talk about how generalized this system is. There are virtually no constraints on how you can get context. You can hook into arbitrary other APIs, or query web pages, or just have your getContext LLM block output SQL queries or even code that you can execute directly. That generalization is a blessing and a curse, however. It's really cool when it works, but you have to deal with wrangling the equally messy / unstructured outputs.
Dealing with Context Length and Further Improving Results with Long Term Memory
In an ideal world, LLMs are not resource constrained — they can ingest arbitrary amounts of data in their string input and can reason over all of it. The real world isn't quite so kind.
In reality, LLMs have a limited 'context window'. There's only a certain fixed input string length that is allowed, that the LLM can reason about at one time. You can think of that context window as the built in state. Any amount of information you can pack into that context window can be used in one shot. Generally, that context is pretty large! Meta's Llama 3.1 and 3.2 models support 128k tokens in a single shot.
However, there are a lot of problems that simply require more data than that. Maybe you want to do something with automated time series logs, or parse thousands of support tickets. Maybe you just need to keep track of a really long IM chain. And most LLM services charge based on tokens, so actually using 128k tokens per request can rack up a pretty big bill pretty quick.
In these situations, you have to do something lossy. You either compress the data and potentially lose nuance and detail that is critical for a final answer. Or you split the data up and create methods for deciding what is necessary to put into the context window when (and potentially risk getting that algorithm wrong). More likely, you do some combination.
The former is often solved with yet another LLM to do summarization. It's exactly what it sounds like: you add an LLM to your system with instructions to summarize the input, and then feed the output into the following parts of the chain as a stand in (side note: hopefully you can see why it's called LangChain).
The latter — create methods for deciding what is necessary to put into the context window when — is a bit more tricky. I bucket solutions to that particular problem as 'long term memory' solutions. Having an LLM write database queries to find the context to feed into another LLM is an example of a 'long term memory' solution. Each individual LLM may not have additional memory, but the system as a whole does.
More generally, long term memory refers to the ability for an LLM powered system to write to a database, and then retrieve information from that database at some later time, thereby artificially 'extending' the context window.
Often it's useful to break down long term memory into 'reads' and 'writes'. These may be done by the same system, but more often are done by two separate systems, asynchronously.

So far everything we've discussed is about how LLMs can read from databases to get additional context. Let's talk about how they can write to databases. From a system architecture perspective, the LLM looks very similar: there's instructions indicating what the database write API looks like, and some data gets passed in to allow the LLM to make a decision about what exactly to write.

Note that the write system may also want to get additional context before making a decision about how to write, which of course can also be an LLM that may want to get even more context, all potentially from the same DB.

Hopefully it's also obvious from here to see how a single LLM system can be fully generalized to read and write and do other things. If you have an LLM system that has, as its input, descriptions for API calls for reading, writing, and calling itself, you can create a multi-step reasoning system with long term memory that can avoid some of the pitfalls of context length.

Follow the lines. You start with an initial prompt and maybe add some context to it. The LLM has three options — it can read, write, or output.
If the model decides it needs to write something, the system will follow the red line. First it writes to the db, then updates the LLM prompt in some way to account for the system state change.
If the model decides it needs to read something, the system will follow the orange line. First it reads from the db (maybe by writing a db query) and then updates the LLM prompt with the new read context. Depending on the specific set of instructions, this system can continue to call itself with more and different context.
Once the system decides it has the answer, it outputs.