


Ilya's 30 Papers to Carmack: Neural Turing Machines

This post is part of a series of paper reviews, covering the ~30 papers Ilya Sutskever sent to John Carmack to learn about AI. To see the rest of the reviews, go here.
Paper 21: Neural Turing Machines
High Level
If you ever want to get a bunch of software people excited, just say that something is a Turing Machine. Software people love Turing Machines. If you search 'accidentally Turing Complete' you will find a bunch of blog posts that collect examples of things that are, well, accidentally Turing Complete.
Why do software people get so excited by Turing Machines and Turing Completeness? A quick history lesson.
If you go way back to the 30s, people were just starting to think more formally about what all this 'computing' nonsense was. People knew it was powerful, but there wasn't any clear understanding of what, exactly, could be represented as a "computer algorithm". Is it…just like basic calculator arithmetic? Is it…all math? Is it…everything in the entire world? People knew that there were likely some formal bounds on computing, but it was extremely difficult to tease out the class of programs that were 'computable' from the 'substrate' of computation. It was obvious that certain kinds of robots could do certain kinds of processes. It was not at all obvious what an 'arbitrary' robot could do, or what it would even look like!
Along comes a young masters student named Alan Turing. He hypothesizes a funny little machine. It looks a bit like this:

There is a long tape1 that is marked out into individual cells. Each cell can have a symbol in it. And there is a scanner that can read one of these cells at a time. Depending on what is in the cell, the scanner can write a new symbol into the cell, and then choose to move left or right along the tape. And Turing makes the claim that this machine can compute all computable programs — that is, anything that can be calculated by a finite, precise set of instructions can be calculated on a Turing Machine.
This is the first abstract computer. And it is a landmark in computability, because it carves out a formal way of describing whether or not a given process is computable. Moreover, the Turing Machine represents an extremely general class of programs. So if you can show that X is a Turing Machine, you can implicitly state that anything a Turing Machine can calculate can also be calculated by X.2 We call this 'Turing Completeness'. Here are some things that are obviously Turing Complete. The device you are reading this from. Every general purpose programming language. Conway's Game of Life.
You know what else is Turing Complete? Magic: The Gathering.

Anything you can do on your computer, you can do in Magic: The Gathering. Yea, sure, it will take a lot longer, but it works. If this doesn't fill you with awe, idk you're probably reading the wrong blog.
Anyway, back to this paper.
The Neural Turing Machine (NTM) is, as you might expect from the name, a neural network architecture inspired by Turing Machines. The NTM isn't as important as actual Turing Machines, but this is probably one of the most important papers in Ilya's canon — it gets cited by almost every other paper we've discussed so far. It's obvious why: the core ideas behind the NTM end up forming the basis for a lot of modern deep neural network architectures, including the transformer and more recently the 2025 Google Titans paper that was doing the rounds a month ago.
Rewind back a decade. It's 2014, and deep neural networks haven't quite taken off. There isn't enough data, there isn't enough compute, the architectures are really unwieldy, the libraries and infrastructure aren't there. Or, more succinctly: neural networks are simply too hard to train. A neural network can, in theory, represent any function. But most functions are actually total garbage. We want our neural networks to only learn a very specific subset of useful functions. The data, compute, infrastructure — all of that serves to make it easier to find the right part of the function space for the model. That's it; all the rest is commentary.
One way to make neural network training easier is to pick an architecture that biases the model to learning a particular kind of function. If you imagine the total space of functions as some high dimensional probability distribution, picking the right architecture increases the weight on a specific part of the distribution.

RNNs are a popular kind of architecture, especially for language tasks. The intuition is that their sequential architecture biases them towards learning functions that depend on strong sequential locality — that is, you can predict n from n - 1. They can empirically carry out transformations of data over many sequential steps. And they are known to be Turing Complete, if you wire them in a certain way.
But RNNs have a known capacity problem.
The standard RNN has to compress a ton of information into a pretty small state space. Obviously, that compression is lossy, which results in signal degradation over long sequences. LSTMs change up the RNN architecture by creating a state "throughline", an uninterrupted residual chain of state that the model can choose to update at each step in the sequence. In theory, LSTMs can selectively store information for an indefinite amount of time by simply learning an identity matrix. And they are a lot more stable to train, because they do addition over sequential steps instead of multiplication. Attention methods improve things even more by allowing the model to search over all previous state and selectively choose which information to work with at each step in the recurrent sequence.
The authors of this paper go a step further. The NTM takes these pieces and adds an additional 'memory bank' tensor that the model can read from and write to at each step. The tensor is an N x W matrix, where N is the number of unique 'memories' and W is the size of each 'memory'.
In order to decide what to read, the model produces a "weighting" vector and then matmuls that vector over the entire memory bank. This is the standard attention operation — a vector x matrix matmul produces a single vector that is the weighted sum of the entire input matrix. In other words, the information present in the matrix will be compressed into a single vector, with the most important data making up most of the information in the output.

Writing is slightly more complicated. During the write step, the model produces a "weighting" vector (as before), an "erase" vector, and an "add" vector. Each index of the weight vector is multiplied by the entire erase vector, producing a vector that represents 'how much data to erase from this row'. That is then subtracted from the memory bank, row by row. The same thing happens with the "add" vector, but with addition instead of subtraction.
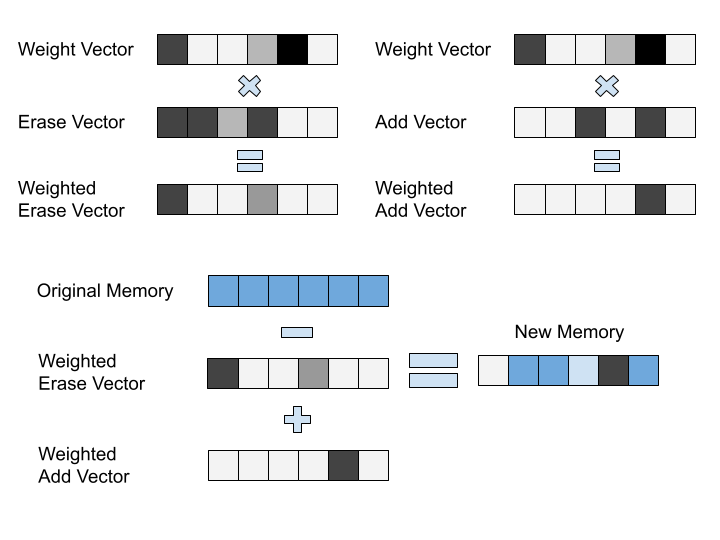
In keeping with the theme, these 'weighting vectors' are called 'memory addresses'.
The NTM can have a bunch of these "heads"; each one can learn different patterns of how to attend to the underlying memory bank. And of course, this whole thing is differentiable, so during training the model will implicitly learn how to produce specific read/write behaviors that are optimized for whatever task at hand. This is fairly powerful, because it means that you do not have to hard code heuristics about what kinds of things your model should store. The model can naturally optimize towards learning read/write functions (and the 'information' being stored) based on the task it is applied to, whether that be basic arithmetic or text translation.
The authors propose two mechanisms to generate these 'memory address' vectors.
One is a straightforward semantic lookup, the kind of search query we are used to from attention. Given an input vector, the model calculates a cosine similarity over every row in the matrix, passes the result through a softmax, and then does a weighted sum of the matrix as defined above. Again, this is literally just attention.
The other is more involved. The authors claim that sometimes we want a more symbolic representation of memory. Quoting from the paper
However, not all problems are well-suited to content-based addressing. In certain tasks the content of a variable is arbitrary, but the variable still needs a recognisable name or address. Arithmetic problems fall into this category: the variable x and the variable y can take on any two values, but the procedure f(x, y) = x × y should still be defined. A controller for this task could take the values of the variables x and y, store them in different addresses, then retrieve them and perform a multiplication algorithm. In this case, the variables are addressed by location, not by content. We call this form of addressing “location-based addressing.
Location based addressing is weird. In addition to the usual “content based” weighting vector (described above for the read/write heads), each head outputs a 'shift vector' of size N, where N is the number of unique rows in the NTM memory bank. If you have only three rows, the shift vector would be a soft maxed vector of size 3, and would represent a shift of -1, 0, or 1 depending on which results had the most weight. To actually perform the shift, each element of the weighting vector i is re-calculated as the sum of each other index multiplied by the corresponding value in the shift index. Once you get the new location-modified weight vector, the read or write proceeds as before.
Note that in practice, the authors don't force the model to output integer shifts in their shift vector. This causes some amount of blurring across rows; the authors discuss a method for sharpening the output as well if needed. One way to think about the shift vector is that it is a way to do a form of self attention. Each index of the weighting vector corresponds to a row in the underlying 'memory' tensor. Given the current input sequence and any internal state, the model effectively decides how to reweight each element on the fly.

The final result allows the model to learn both content and location based addressing, depending on how much weight it puts on one part of the addressing system over the other.
When combined with a LSTM for the "controller" that reads in the input sequence, you have a model with two layers of memory addressing. You could analogize this to a CPU; the LSTM internal layer acts like "registers", and the memory bank acts like "RAM". The authors mention that you could use a MLP for your controller network instead, but this would basically just end up looking like an LSTM.
Put it all together, and you get something that looks like this:

Earlier, I mentioned that the whole point of a model architecture is to bias the model. We want to find architectures that do better at learning specific kinds of functions. This leads us to a natural question: what can a NTM do that a regular LSTM can't do?
Well, the point of the NTM is to increase the effective context window. This is a bit of an anachronistic term, since today it refers to the usable input sequence length in transformer architectures. Still, the general idea is the same: RNNs do reasonably well over small snippets and start performing poorly over longer snippets as things fall out of their "memory". So the authors have a bunch of experiments that test the long term recall of the model, all of which look pretty similar to modern day benchmarks for long context window analysis. For example, the authors have a "copy task" in which they try to perfectly output an input sequence using various neural network architectures, and they find that the NTM performs well even when compared to an equivalently sized LSTM.

Because they are using an attention-inspired system for memory addressing, the authors are able to peer into the NTM to see what algorithms the read and write heads learn. For each input vector, there is a corresponding memory slot that the model attends to on write, which increases linearly for each new input. And the same pattern is repeated on read, showing roughly how the model learns the copy task and utilizes location-based addressing. Importantly, the model learns this program from the training data alone.

Insights
I have mixed feelings about this paper. On the one hand, it is clearly so influential for everything that came after it. But on the flip side, the paper is really full of itself. It makes these grand evocative gestures towards Turing Machines and cognitive science3, all of which feels more like SEO optimization than anything formally insightful. I think it's worth going through all of the bits and pieces that tie into the themes we've been exploring in this series; just note that even though we started with this really compelling story about Turing Completeness, the paper doesn't quite reach those lofty goals.
In my opinion, the most interesting part of this paper is the explicit implementation of multiple read and write heads. NTMs are optimized for specific tasks, like translation or auto regressive generation. A single head is a bit like a single convolution filter — during training, it learns a fixed "stamp" that it uses to manipulate data in the memory bank, in the same way a single convolution filter will learn a "stamp" that represents an edge detector.4 In keeping with the Turing Machine framing, the paper explicitly thinks of these heads as learned programs. For example, there is some read/write head that learns the "increment memory counter and store data" program.
All of this is, of course, a direct ancestor for attention heads in LLMs. Naively, it's tempting to think of a transformer as a kind of dynamic, input-dependent architecture. And there is some truth to this — the self attention matrices that allow each word to attend to all other words is itself a product of the word embeddings. But you need multiple attention heads precisely because these self attention matrices can't learn new programs after training — they are fundamentally deterministic. As we've seen over and over in this paper review series, architectures that allow for separating programs from representation, and programs from other programs, learn more complex classes of functions more efficiently. So the transformer requires multiple attention heads, for the same reason convolutional networks require multiple filters and the NTM requires multiple read/write matrices. Each attention head in a transformer learns a specific attention "stamp" over the input text sequence. And interpretability researchers have discovered that these heads will also learn programs that are useful to untangle meaning from a block of text. You may have a head that will learn to highlight the first occurrence of a character's name, or one that will learn to attend to adjectives describing a noun. The more attention heads, the more programs you can learn over the data.

Even though the authors spend a lot of time talking about the ingenuity of their memory bank architecture, I found that to be comparatively less novel. The basic shape of the NTM is an LSTM, something even the authors explicitly call out. Both the NTM and the LSTM have this throughline of state that is dynamically read from and written to based on the input sequence. Sure, the NTM reads from that state using attention while the LSTM does not, but the concept of 'writing' is essentially identical to the 'forget / input / output' gates. I think it is somewhat interesting that a NTM with an LSTM controller has two sets of state — an 'inner' hidden state from the LSTM, and an 'outer' memory bank state from the NTM. But it's not obvious that this structure actually results in better outcomes.
The last thought that I have is that the location based addressing described in this paper is pretty unique. I'm not aware of other papers that really followed up on that particular architecture. It's no surprise why: information stored in tensors is fundamentally continuous, and operations across tensors are blurred by probability distributions and softmaxes. Nothing ever really goes to 0 perfectly. As a result, any attempt to do strict location based indexing is always going to feel like swimming upstream.
Even though I described the NTM 'shift vector' above as a straightforward index, in practice the shift vector output is a probability distribution. You don't get clean 0s and 1s, you get this fuzzy weighting across all of the indices at the same time. The authors have multiple mechanisms to try and 'sharpen' the output, successively putting more weight on specific indices. But these are all cludges, and I get the sense that they don't really work that well. More generally, I suspect that you can't really ever do purely symbolic reasoning through a neural network. Luckily, it seems that LLMs are good enough at writing code that they can leverage other systems to do symbolic reasoning for them.
Remember that back then, long tapes were more or less how things like telegraph transmissions were recorded.
None of this is formally proven. Much like the theory of evolution, the Church-Turing thesis is still just a thesis. It's unclear how you would even go about proving this. But it seems likely that all of this is true nonetheless.
I didn't mention this in the review, but the paper opens with a section on "working memory" models in neuroscience.
This isn't an original idea, I got it from the Attention Free Transformers paper.