


Ilya's 30 Papers to Carmack: Pointer Networks, Conv Nets

This post is part of a series of paper reviews, covering the ~30 papers Ilya Sutskever sent to John Carmack to learn about AI. To see the rest of the reviews, go here.
Paper 7: Pointer Networks
High Level Summary
LSTMs are great for learning over sequential data. One way to use them is through a sequence-to-sequence model, for tasks like translation. Roughly, you have two RNNs. One RNN calculates a hidden state for each part of a sequence (an encoder). The other RNN turns that hidden state into a prediction of what should come next (a decoder). During training, you run these together, with the loss coming from the next-word-prediction in a sentence. For example, “The quick brown dog jumped over the lazy fox”, the encoder will first encode “The”, then “The quick”, then “The quick brown”, etc. while the decoder will try to predict “quick”, then “brown”, etc1 2. During inference, you can feed the outputs of the decoder back through the encoder to create an arbitrary-length text generator.
I have fond memories of the seq2seq model — it was the first kind of model I ever trained. Unfortunately, it doesn’t really work very well.
One issue is that long sequences result in information loss, a pretty common problem with RNNs. In particular, a traditional seq2seq model will encode a ‘prefix embedding’, and the decoder tries to predict the next word from the prefix. In other words, the RNN has to jam all the information it can about the sequence into that last output embedding. That kinda sucks.
One way to fix this is with attention. The core idea behind attention is that the model should be able to learn which part of a sequence is most relevant to predicting the current word. The original attention mechanism involved training another neural net on top of the seq2seq model.
Say you wanted to create an attention vector for token i. You would take the decoder hidden state for that token, and the encoder hidden states for all tokens generated thus far. You would then generate a set of ‘scores’. Each score is a function of the decoder hidden state and one of the encoder hidden states. You softmax over the set of scores to create your attention vector. And then you use that attention vector to collapse all of the other encoder states into one ‘context vector’, weighted by the scores.
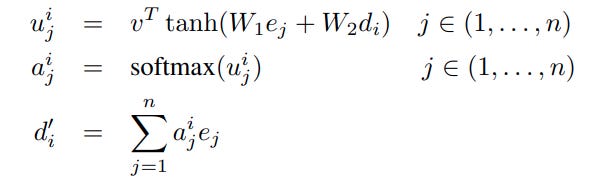
The original attention paper just concatenates the attention context vector to the decoder hidden state and lets the decoder do its thing. Obviously, attention as a concept has come a long way since then.
One other issue with seq2seq models is that they can’t dynamically change the output dictionary based on the input. Remember that all tokens in a sequence need to be turned into ‘embedded vocabularies’. The seq2seq requires that the input vocabulary and the output vocabulary are fixed throughout training. This works fine for language generation, where you just have literal vocabularies. But there are some trivial examples where this limitation sucks. For example, if you were trying to sort a list of numbers, you don’t want your model to start outputting things that aren’t in the original input list.
The paper proposes pointer networks as a fix to this latter problem.
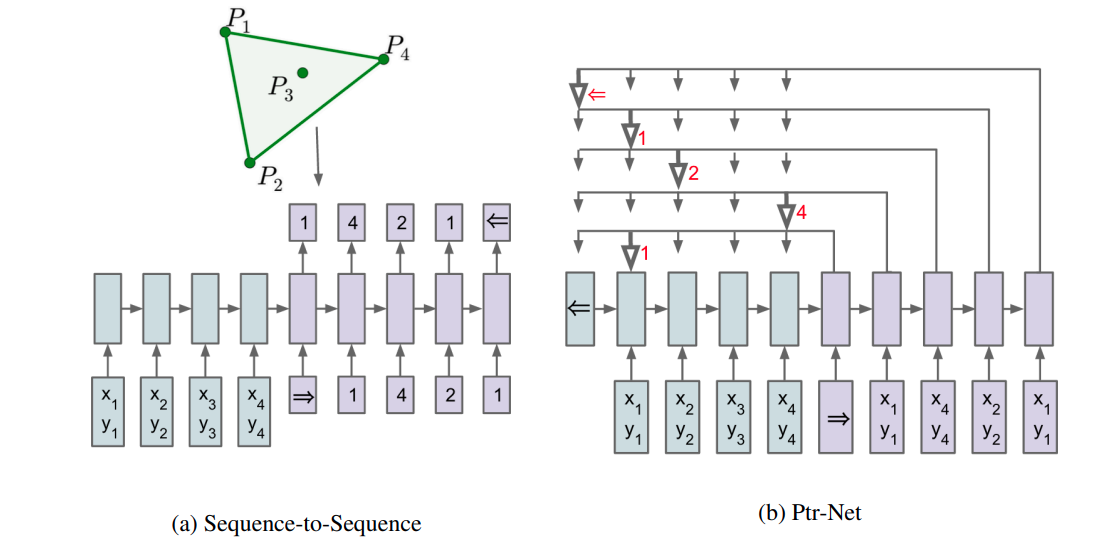
The core idea is that you can use the same attention vector described above to literally point to a specific input index, and then use that index as your output. Say you were sorting a list of size S. At each step in the sequence the PtrNet would output a vector of size S. The index of the largest value in the vector would map back to a specific index in the list.
Insights
There is a type of ML paper that is roughly about identifying some class of problems that existing models struggle with, and then modifying it slightly or adding some twist to make that model work on the new class of problems. This can feel foreign in 2024 because foundation models exist — the whole point of foundation models is for one model to be generalizable to a wide range of tasks. But back in the olden days, we really did train different models for like every different class of problem3.
The main insight that the authors have is that attention allows for dynamic lookups on the input. The traditional way to train a seq2seq model is on a fixed length input. In practice, your sequences are variable length, so you pad out or crop your sequences until they are all the same size. But by using attention, you can remove any need for a fixed length output entirely.
I am a bit torn about this paper. On the one hand, it’s quite limited. The solution described really only works for the subclass of problems where the output space is equal to the length of the input, and in particular where the outputs correspond to positions on the input. There’s not a ton of problems out there that fit into this category. On the other hand, the model does a pretty good job learning to solve an NP hard problem like travelling salesman. That’s pretty cool!
I think the most important part of this paper is how it fits into the story of transformers. It’s easy to look at a transformer and think, “Wow, what an elegant building block, how did know one else think of this!” and the reality is, a lot of people were tinkering with attention as a means to generalize and improve language modeling. Pointer networks ended up being a bit of a side tangent in this story, but you can start to see the threads of how these papers evolve in tandem — the core of the transformer is a lookup table, much like how pointer networks literally ‘look up’ the relevant index as their output.
Paper 8: ImageNet Classification with Deep Convolutional Neural Networks
High Level Summary
This one is a classic, arguably the paper that kicked off the deep learning boom. You may know it as AlexNet. This paper is the first time a deep learning model really kicked ass against ‘traditional’ methods of computation on basically any task.
This is the first paper in our list that is an engineering paper, through and through. The paper starts by describing the benchmark (Section 2) then goes through a list of what are essentially hacks to get a big convolutional network working on the dataset in question (Sections 3-4), and finally does some qualitative and quantitative evals (Sections 5-6). It never really spends much time theoretically motivating why the authors make the decisions that they do; it’s sufficient that changes lead to better outcomes on the test data that they care about.
So many of these architecture decisions are so well known in the industry at this point that I don’t feel compelled to spend a ton of time on them. To be honest, that’s not really why this paper got famous anyway. The biggest draw of this paper is that it worked. It’s a benchmark setting paper, the first in a long line that stretches from AlexNet all the way to AlphaFold. The unreasonable efficacy of neural networks indeed.
Insights
I think what’s cool about this paper is that you see early hints of the scaling hypothesis debate that would later make Ilya famous at OpenAI. The core thesis that the authors of this paper have is that they need a really big model to learn the image dataset. But in order to get a really big model, they have to do all these hacks to get the thing training in a reasonable amount of time on a reasonable hardware setup. As a result, there’s a ton of focus on speed (relu as an activation functions, gpu kernels — including what is I think the first ever GPU implementation of a convolutional layer?, multi-gpu training). And, again, there’s a focus on test quality over theoretical reasoning — for example, they basically justify using overlapping pooling through empirical analysis alone.

The paper authors run into a problem though — there isn’t enough data, the model overfits, and normal regularization doesn’t seem to cut it. So they dramatically expand the amount of data they have by artificially augmenting it, a practice that is essentially industry standard now. This is maybe the first time we see an explicit balancing act between the amount of data that’s available to train and model size. Approximately 8 years after this paper comes out, Scaling Laws for Autoregressive Transformers appears. That paper empirically shows that model quality is power-law-dependent on model size and dataset size. A nice follow up to AlexNet.
Two last things to mention:
First, the paper dips briefly into neural net interpretability. It’s really fascinating that the two GPU arms of the model specialize to learn different kinds of kernels!4 I doubt that this paper is the first example of this kind of analysis, but it’s certainly a very prominent one.
Second, the paper also begins to pick at representation learning when it says the following:

Very cool to see how these areas have evolved since the early days when we were still grasping at how deep neural nets could be used.
Since both the encoder and decoder retain an intermediate state, the overall process is linear in sequence length. They don’t literally compute each prefix every step; they retain information as the sequence progresses. Transformers are quadratic because they do compute each prefix every step.
Note that the decoder technically doesn’t have to be an RNN too. It’s just better if it is an RNN, because it can pass along hidden state from the inputs (where it knows what the next step in the sequence should be) to new generations (during inference).
Translation, summarization, captioning, question-answering, text generation — these were all seen as different problems requiring different specialized models! Now we just throw ChatGPT at all of them.
Even more interesting is the fact that the authors clearly didn’t intend for specialization to occur across GPUs. I’m pretty sure they just wanted a 6GB model and had 2 3GB GPUs to work with; if they could get their hands on a bigger GPU they would probably just stuff the whole model onto that and we’d never see this specialization result.