


Ilya's 30 Papers to Carmack: Scaling Models with Parallelism

This post is part of a series of paper reviews, covering the ~30 papers Ilya Sutskever sent to John Carmack to learn about AI. To see the rest of the reviews, go here.
Paper 10: GPIPE: Easy Scaling with Micro-Batch Pipeline Parallelism
High Level
Ah, another engineering paper.
It turns out there's a strong correlation between model performance and size. So we want bigger and bigger models. At some point, though, we run into practical issues — namely, our chips aren't big enough. So how do we scale?
Broadly, you have a big model that is too big to fit on a single chip. So you need to split it up among some number of chips. You can think of the single-chip performance as an upper bound — that is, you want to select the strategy that most closely approximates running the model on a single, really big chip. There are a ton of strategies for how you could do this. None of them are perfect, all of them have some trade-offs. Generally, the biggest thing to worry about is the efficiency of communication between chips, because that is where you are introducing overhead. But often you care about how much memory is on a single chip, or how much sequential compute you have to do, or any number of a wide range of things.
For deep learning models, you can broadly do one of two things: you can split vertically, by putting different complete layers on single chips; or you can split horizontally, by putting the same layer on multiple chips.
GPIPE is basically all technical implementation about how to scale models vertically. The core idea is straightforward: since models are composed of a bunch of layers, we can split the model by layer(s) and run each set of layers on a given chip and have the outputs of one chip feed into the inputs of the next (and backwards for gradient propagation). For example, if I have a model with 100 layers, and I have 4 GPUs, I put the first 25 layers in chip 1, the second 25 on chip 2, and so on. During the forward pass, we calculate the outputs of chip 1 and pass it to chip 2. During the backward pass, we do the opposite.
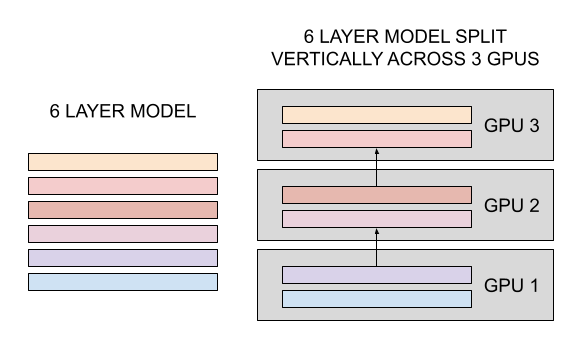
You may have spotted a problem here — this implementation would work, but it would be pretty inefficient. In particular, you'd be 4x less efficient than usual, because your GPUs just end up sitting around idling while the rest of the sequence finishes. GPIPE has an answer: we use pipelining (thus the name)! Split a batch into a bunch of 'microbatches'. Pass in a microbatch; as each layer finishes, you immediately pipe in the next microbatch. You can then compile gradients over these microbatches to get a single 'large' batch and apply it all at once.

This significantly decreases the performance dropoff in 'the bubble', allowing for much larger models without a meaningfully significant increase in training time. In particular, they find that 'bubble overhead is negligible if the number of microbatches >= 4x the number of GPUs being run on'.
But, wait, another issue: how do we deal with memory? If we parallelize across batches, a single accelerator may have to maintain state for many batches at the same time in order to eventually calculate the backward pass. In order to get around this, GPIPE supports 'rematerialization' — that is, only storing the inputs for each batch, and then rerunning the forward pass for just that accelerator during the backwards pass to get all the parameters necessary to calculate chain rule gradients.
This all makes GPIPE really efficient — the authors claim 3.5x speedups from 4x the number of processors, a near linear parallelization improvement.
What are the tradeoffs?
Well, early on I mentioned that you can scale vertically or horizontally. Generally, horizontal scaling (also known as SPMD, or single-program multi-data) means taking a single mat-mul operation and splitting it across many different devices.
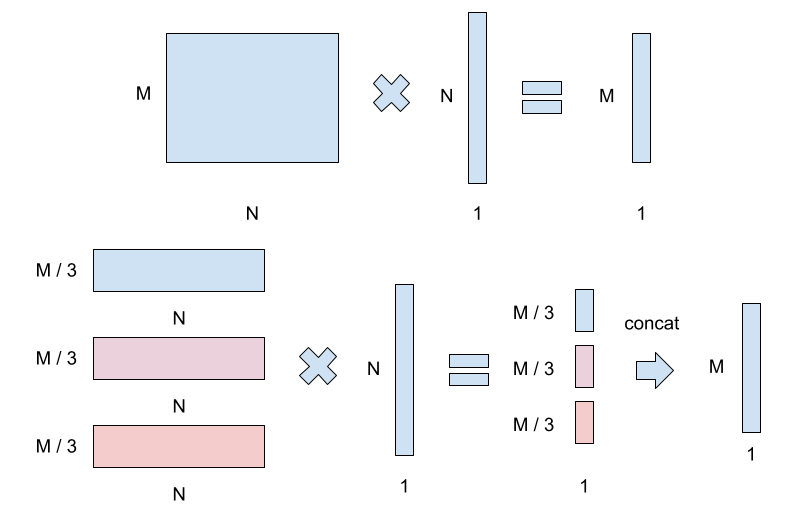
Horizontal model splitting allows for much larger model layers, but you have to do a lot more communication between chips. This functionally limits your deployment to settings where you have high speed interconnects. Besides being more costly, you're also limited in the kinds of operations that you can split. And of course, there's a fair bit of additional mental overhead for maintainers. If you need a really large horizontal layer, it can't be helped. And if you really care about utilization, I think SPMD may be better. But the authors of GPIPE implicitly — and I explicitly — make the claim that where possible, vertical splitting is simply better than horizontal.
There are other types of pipeline parallelism besides GPIPE. The biggest trade-off is that GPIPE requires splitting batches into smaller, micro-batches. This can be problematic if you have layers that calculate per-batch statistics, like BatchNorm. But for the most part, as of the publication of this paper (2019), if you are doing pipeline parallelism you probably should just use GPIPE or equivalent.
Insights
I think this paper is pretty straightforward. There's not much 'intuition building' here — even though the nature of how deep learning works is, essentially, a total mystery, training ML models is fairly well understood. There are things we can easily measure, like throughput and training times and utilization, that are easily optimized and mostly abstracted away from the specifics of deep learning architectures. The one interesting note is that this paper is downstream of the model scaling hypothesis being proven true (for at least some range of models). I think for many, it became obvious that model scaling was the way to go with the release of GPT3 in 2020. But inside Google, folks had been training super large models for quite some time1.
As far as optimization goes, there are a bunch of other things that can be done to make models bigger and faster. These vary for training and inference (generally, it's easier to optimize the latter). There's all sorts of caching algorithms. More generally, if you know your model architecture a priori, you can take steps to optimize specific computations2. If this sounds like a standard distributed systems problem, that's because it is3. If you have a good intuition for building applications that have to run across many different devices, and have to deal with problems like availability, redundancy, throughput, latency, and so on, you likely will have a good intuition for model parallelism.
As a final note, I spent some time looking for what the state of the art is for model parallelism in 2024. I think as time has gone on, the optimization approaches have become more niche. GPIPE works for any large model; something like KV caching or GQA grouping really only works for LLMs4. That's not to say there's been no progress. Flash Attention exploits chip layouts to get much faster GPU IO with no theoretical model tradeoffs. Quantization reduces model float precision, making every computation faster with some small accuracy hit. More generally, folks have released packages like Megatron (NVIDIA), DeepSpeed (Microsoft), and GPT-NeoX (Eleuther) that are meant to make optimal parallelization techniques as easy as drop-in function replacements. There's a whole industry of training infra that simply didn't exist a few years ago. Eventually we might get something like K8s that just becomes the industry standard, but for now it's (still) the wild west and there are a few players jostling for that top spot5.
Which makes it all the more disappointing and surprising that they are now playing catch-up
Because Transformers are so dominant, there's been a fair bit of work in making self-attention particularly efficient. The KV cache is a popular approach for making transformer layers faster during inference, for example.
For some reason modern ML people pretend that training really big models is somehow different from distributed systems. I think this is just a way to jack up salaries.
Both caching mechanisms that store off specific attention computations that, in a naive setting, are recalculated exactly multiple times.
Interestingly, it looks like Google themselves hasn’t really released an equivalent package like GPIPE in some time. I may have just missed it, but this could be because Google has moved a lot of their large model training to internal-only TPUs, which may have different performance characteristics.