
LLMs are Programming Languages: A Review of Voyager (Part 2)
Dissecting Minecraft Steve

This is Part 2 of a two part series. Part 1 can be found here.
So, who's played Minecraft?

Turns out, Minecraft is a really hard game. Not hard for humans, of course — my 3yo cousin plays Minecraft. But it's maybe uniquely difficult for AI. Consider:
There's no predefined goal or story;
It's in first-person 3D, so you have an 'embodied' actor who has a (more or less) continuous action space;
There are tons of long running tasks that are composites of other tasks;
And the whole thing is procedural, with completely random/dynamically generated worlds.
Minecraft agents need to display all of the properties of 'life long learning', i.e. continuous advancement and improvement. It's pretty straightforward to make an AI that only chops wood, but it's a real pain to make one that can competently do everything that Minecraft has to offer.
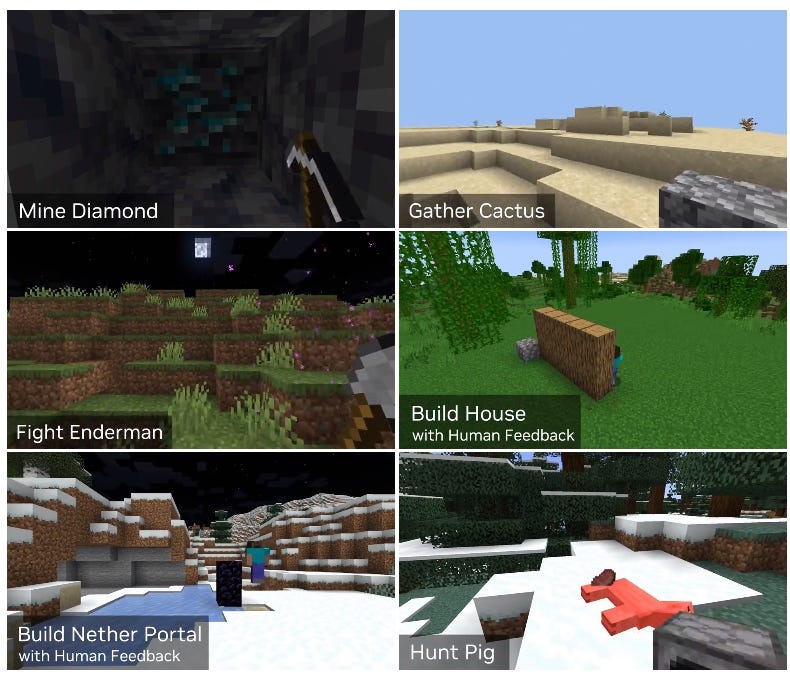
Voyager can do all of the above and more.
Voyager is the name of an embodied agent that uses multiple LLMs to 'solve' Minecraft. Each LLM is programmed with a different prompt. The LLMs take in game state, and sometimes one or more outputs of other LLMs. A final LLM writes code that is used to execute actions in game, and then the whole process repeats.
The Voyager agent is composed of three modules: a 'curriculum' generator, a skill library, and a code generator/task validator. Let's go through each one to see what LLM programming looks like in action.
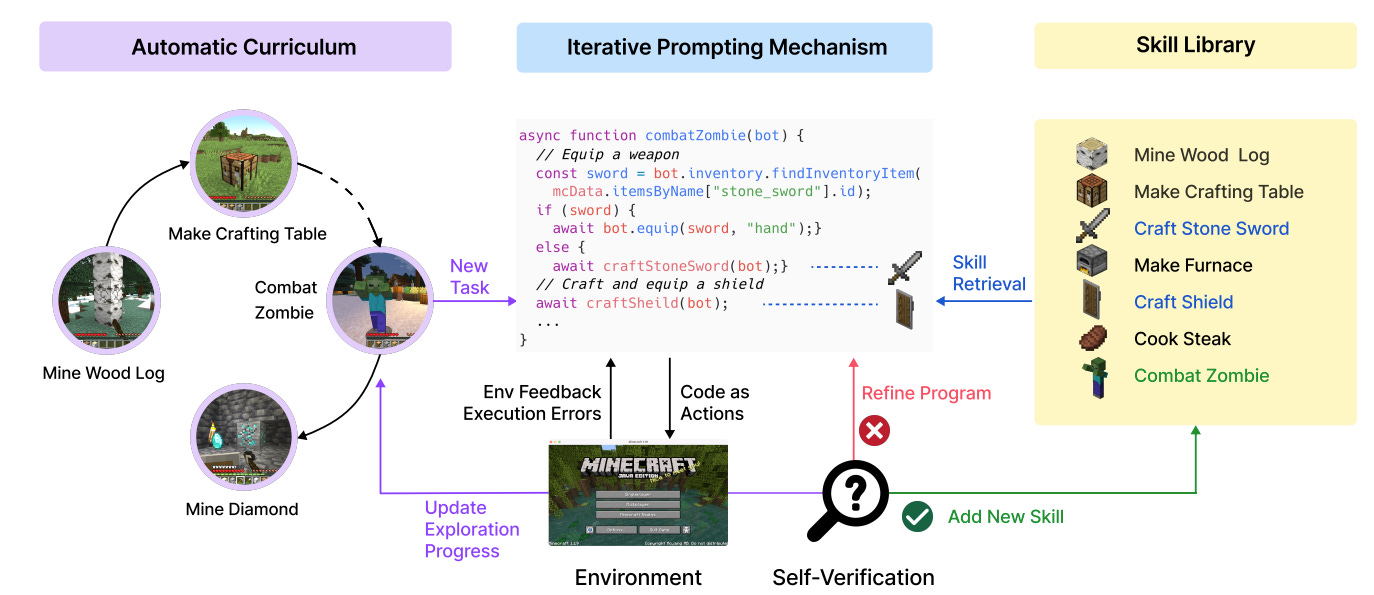
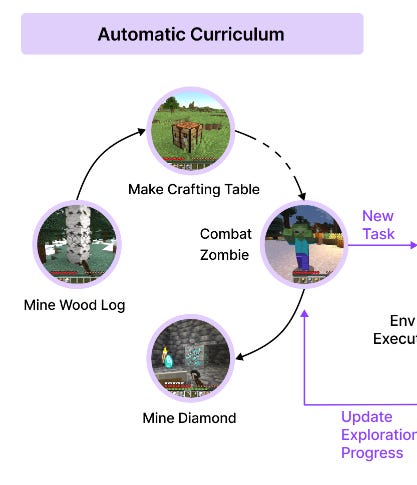
The Curriculum Generator
The goal of the curriculum module is to create 'tasks' for the agent based on the current game state. The module is itself comprised of four different LLM prompts:
A question generator that takes in the game state and produces a set of questions;
A question answerer, that takes in the game state and the above questions and answers them;
A task generator, which takes in the state and the results of both of the above LLM prompts;
A task generator, which takes in all of the above and produces subtasks.
I can't really explain how wild the curriculum module is. So instead the best I can do is just copy paste some "code".
You are a helpful assistant that tells me the next immediate task to do in Minecraft. My ultimate goal is to discover as many diverse things as possible, accomplish as many diverse tasks as possible and become the best Minecraft player in the world.
I will give you the following information:
Question 1: ...
Answer: ...
Question 2: ...
Answer: ...
Biome: ...
Time: ...
Nearby blocks: ...
Other blocks that are recently seen: ...
Nearby entities (nearest to farthest): ...
Health: Higher than 15 means I'm healthy.
Hunger: Higher than 15 means I'm not hungry.
Position: ...
Completed tasks so far: ...
Failed tasks that are too hard: ...Like, what?!
Imagine programming in Python and trying to encode "best Minecraft player in the world", what does that even mean? But this is the beauty of LLM programming. We don't need to have a formal solution. We just have to set out a goal, and some IO.
O sure, it's not quite that simple. We of course we have to provide some guidance:
You must follow the following criteria:
1) You should act as a mentor and guide me to the next task based on my progress.
2) Please be very specific about what resources I need to collect, what I need to craft, or what mobs I need to kill.
3) The next task should follow a concise format, such as "Mine [quantity] [block]", "Craft [quantity] [item]", "Smelt [quantity] [item]", "Kill [quantity] [mob]", "Cook [quantity] [food]", "Equip [item]" etc. It should be a single phrase. Do not propose multiple tasks at the same time. Do not mention anything else.
4) The next task should not be too hard since I may not have the necessary resources or have learned enough skills to complete it yet.
5) The next task should be novel and interesting. I should look for rare resources, upgrade my equipment and tools using better materials, and discover new things. I should not be doing the same thing over and over again.
6) I may sometimes need to repeat some tasks if I need to collect more resources to complete more difficult tasks. Only repeat tasks if necessary.And provide a response format, with a few examples:
You should only respond in the format as described below:
RESPONSE FORMAT:
Reasoning: Based on the information I listed above, do reasoning about what the next task should be.
Task: The next task.
Here's an example response:
Reasoning: The inventory is empty now, chop down a tree to get some wood.
Task: Obtain a wood log.But that's it. That's all we need to have our curriculum generator work.
To me, this is actually nuts. To break this down a bit, we're using an LLM to populate a set of questions, which is fed into an LLM to generate answers, which are then fed into another LLM to create a TODO list. If this runs consistently in a loop, we will generate a steady list of new, relevant tasks. And at no point did we have to actually determine what it means to 'solve' Minecraft. The AI just does it for us.
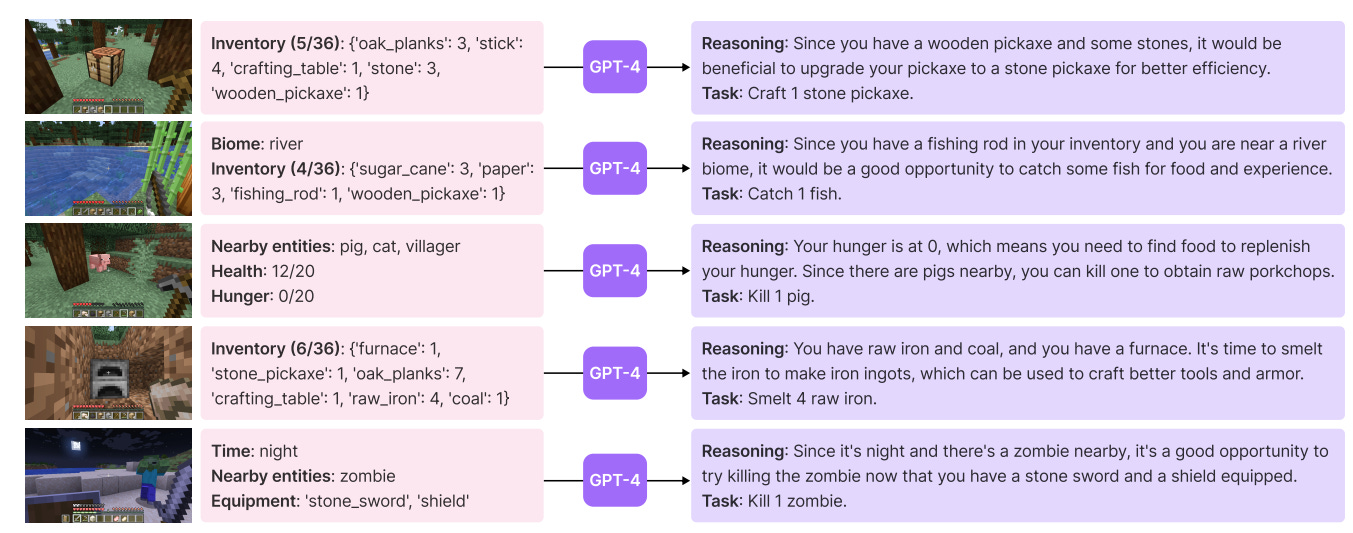
I think what's so crazy about the Voyager paper is that the entire codebase is like this. It's maybe a few thousand lines of code, with the vast majority of those lines being in English. Seriously, just go read the thing.
Skill Library
Ok, so we have a tool that gives us an increasingly complex set of tasks. That complexity comes from composition — certain tasks build on a prior understanding of other tasks. We know that fulfilling those tasks requires some amount of code, but it seems tricky to expect even the best LLM to go from a task description directly to perfect code. We want to give the agent some 'memory', so that it isn't deriving 'how do I build a pickaxe' from first principles ten hours into the game.
The answer is the skill library. At its core, the skill library gives us a way to go from the current game state and task list to a set of previously-written functions that may serve as a useful API.
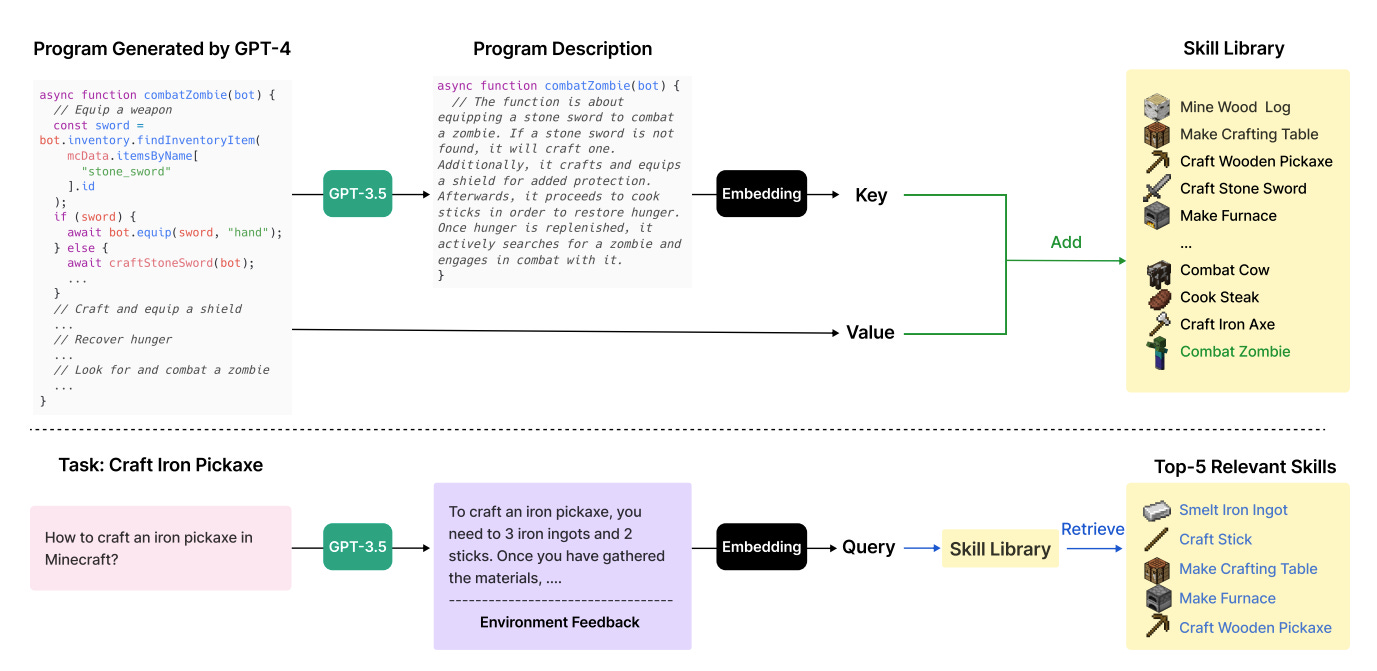
Let's say we have some code that lets Minecraft Steve fight some zombies.
First, we ask an LLM to write a comment that summarizes what the code does. The summary might look something like: "Equip a stone sword to combat a zombie. If a stone sword is not found, create one first. Also craft a shield. Then search around until you find a zombie and fight it."
We then embed that summary, and store it in an embedding database. Think of an embedding database as a key value store, where the key is a point in space. When we do lookups, our query is another point in space, and our results are all of the other points that are nearby, ordered by distance.
When the agent is in game, we ask an LLM to write a summary of what kind of information is necessary to complete it's current task list. We then embed that summary, and use it to query the database. The result is a set of functions ordered by usefulness. So, if our environment says something like "there is a zombie nearby", we might expect the embedding database to return our "combat zombie" function.
Once we have a set of useful 'skills', we can finally do…
Codegen and Validation
Once we understand the skill library, the codegen is fairly straightforward. An LLM takes in the agent state and uses it to query the skill library to get some functions that may be useful. It then tries to generate some code, possibly calling out to the functions surfaced by the skill library. And finally, the agent runs the code.
After the code is run, we want to make sure that we actually accomplished the task at hand. We do that with (you guessed it!) an LLM. We feed in the agent state after the code has run, and use it to determine whether the underlying task is completed. If the task succeeds, we add the newly generated code to the code library. If not, we ask the LLM for a specific reason why the task did not succeed, and then feed this 'critique' back into the top of the codegen module to try again.
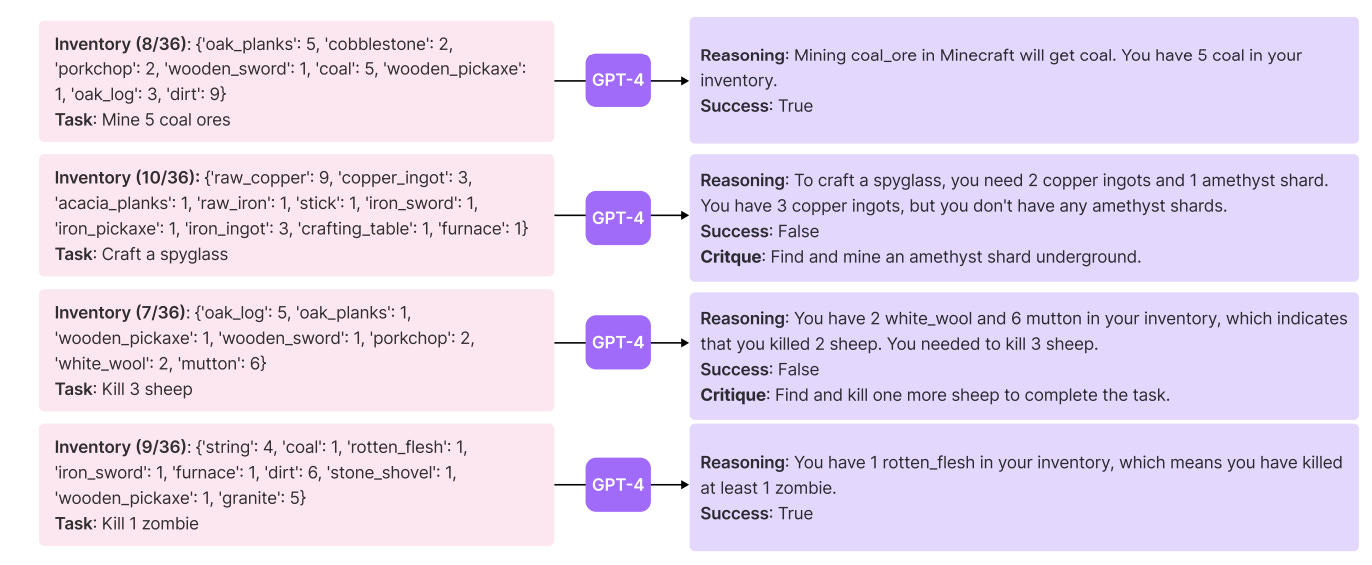
I want to spend a minute talking about this critique system, because I think it's really interesting and I have a lot of thoughts.
One of the most significant complaints leveled against LLMs and their ilk is that they 'hallucinate' — that is, they will confidently output incorrect answers to common sense questions, including mathematical questions. I think the critique system found in Voyager is a fairly strong response to these complaints. Instead of blindly trusting the LLM, we should fact check it; and the fact checker can be an entirely different automated system.
But why stop at one fact checker? We could in fact conceive of a system where there is another fact checking LLM validating the output of the first two LLMs. And maybe we have another LLM on top of that, and another one, and another one, and …

Theoretical ML is still in its infancy, but an early win is the boosting hypothesis. Very roughly, boosting says that if you can construct a classifier that is slightly better than random (50.00001% accurate in a binary task) then it is both theoretically and practically possible to create a classifier that has arbitrary precision (99.999999% accuracy) by assembling many weak classifiers together into a single system.

I think you can construct a roughly parallel hypothesis with LLM fact checkers. Or, in other words, maybe the hallucination problem goes away entirely if you just stack enough validators.
There are (probably unintentional) echoes of GANs here. You can think of these two models as being adversarial, with one trying to convince the other. The beauty of GANs was always in their elegance. Instead of coming up with your own loss function, let the AI do it! The problem with GANs was also their elegance — there were too few constraints on the overall system, resulting in frequent descents into instability chaos. Having one LLM fact check another retains some of the original elegance of the GAN architecture, while introducing many more constraints (namely: both of the LLMs in the system are heavily pre-trained on different objectives).
What can Voyager do?

Before we go through a quick smattering of results, I do want to mention the baselines. Voyager is in many ways a first-of-its-kind agent. There aren't really a lot of other agents that have even tried to take on Minecraft. So in order to do comparisons, the Voyager team had to create agents using other published algorithms. In situations like this one, it's always possible to levy some amount of skepticism — maybe Voyager is 'competing' against worse implementations of its 'opponents'? But I don't fault the Voyager team for not spending a ton of time on improving the competition. And I think the order of magnitude improvements we see in Voyager suggests that its successes are relatively real.
With that out of the way, let's look at some graphs.
First maps.
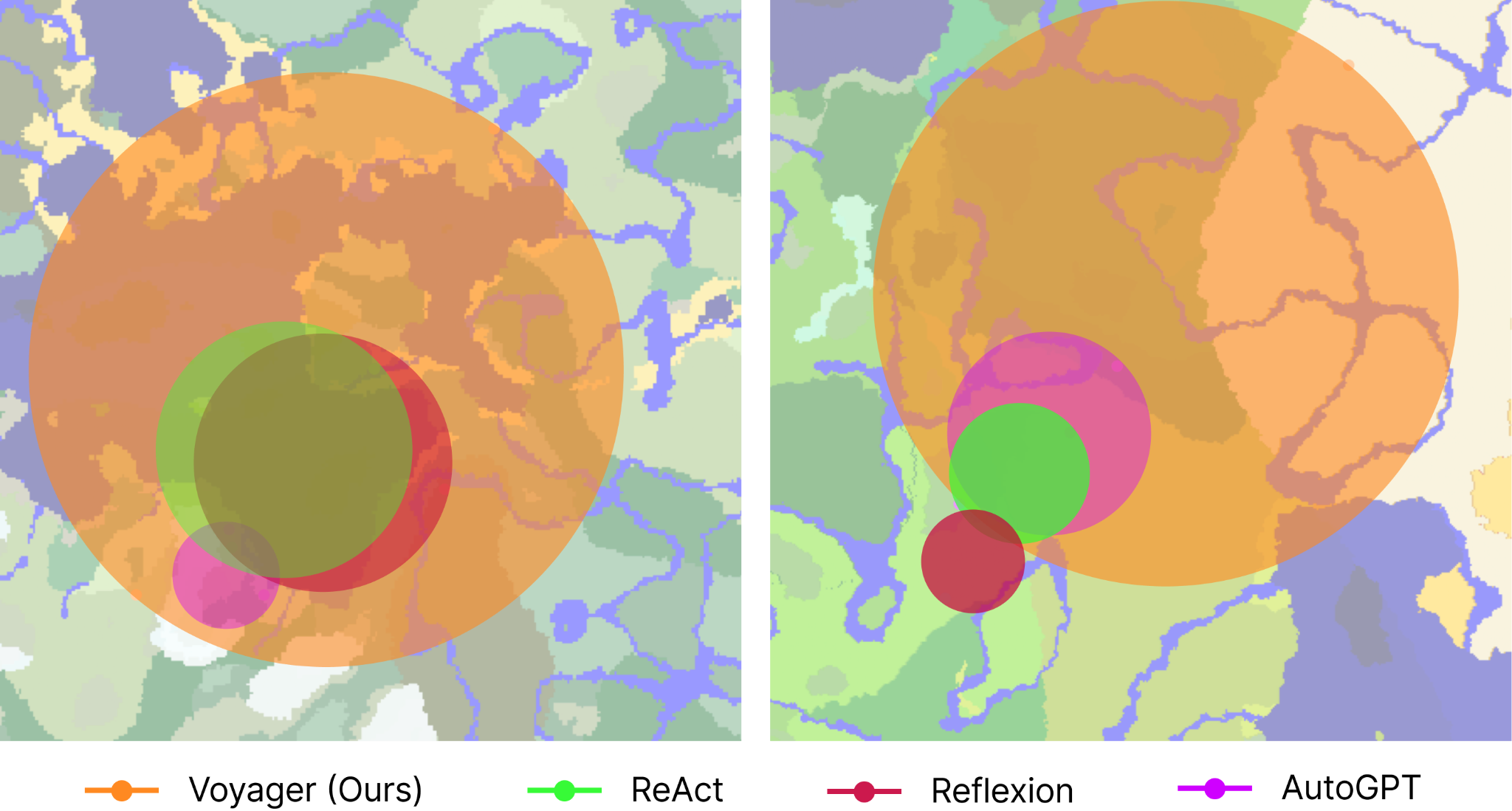
Voyager is able to navigate distances 2.3x longer compared to baselines by traversing a variety of terrains, while the baseline agents often find themselves confined to local areas, which significantly hampers their capacity to discover new knowledge. There is something of an interesting feedback loop here — by being able to explore more area, Voyager is able to experience and discover more materials, which in turn results in wider exploration. Less 'intelligent' agents end up getting stuck in smaller corners of the map.
Second, discovery.
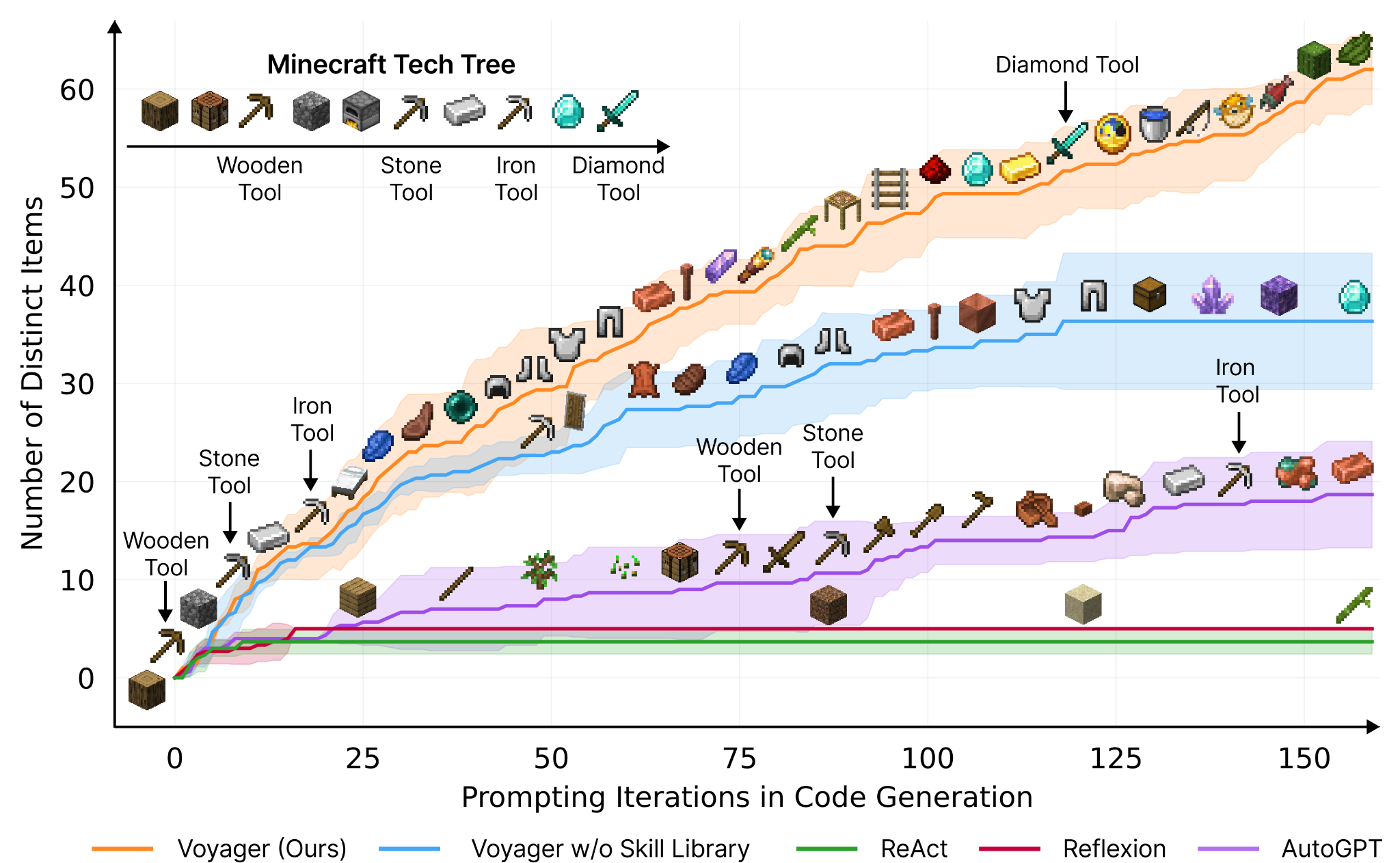
The Voyager AI walks the skill tree of Minecraft pretty effectively, far outpacing competitors which (in some places) never go past mining basic blocks. The x axis here is computational steps instead of game time, which can be a bit deceiving — imo, the biggest weakness of Voyager is that it has to pause the entire game engine every time it decides its next move.
Finally, ablation.
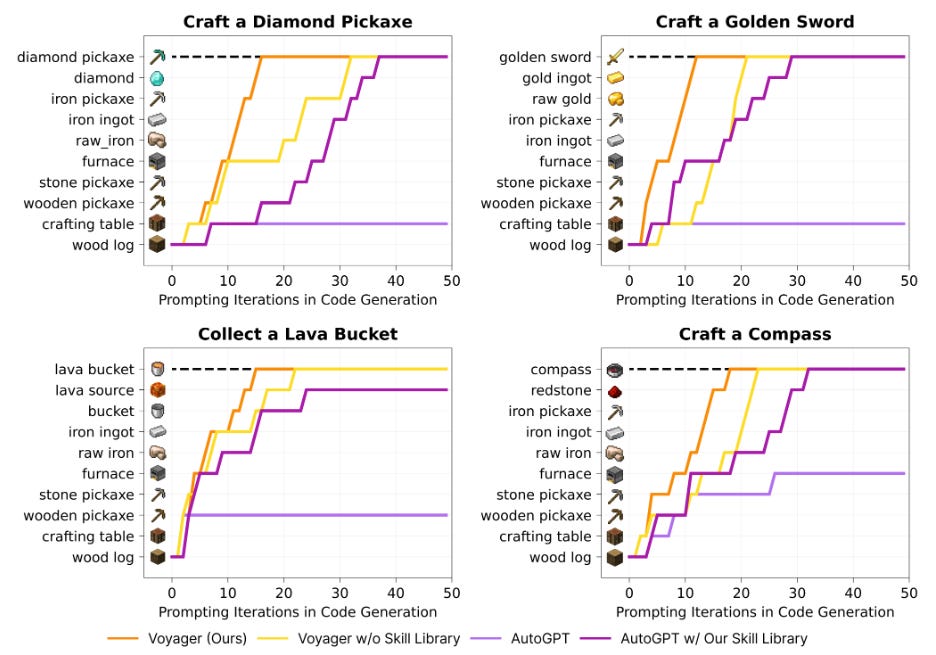
Minecraft is a random game, so we care about how well the Voyager AI is able to learn in new conditions. So the researchers clear the agent's inventory and ask it to perform previously unseen tasks. The table above shows the number of successful trials given differing amounts of prompting iteration.
Conclusions
Voyager is an AI that plays Minecraft. That alone is a cool result. There's definitely more juice to squeeze in the realm of agentic AI — in the next few years, I think we can expect the rebound of AI-powered assistants for specific tasks like programming. A few papers and open source projects are already heading in this direction. The self-learning capabilities of Voyager are also fairly impressive because they allow for higher order reasoning, and I can imagine various products integrating some elements of the 'skill library' into their stacks.
But for me, the main headline is a bit higher level. Instead of focusing on the 'what' of Voyager, I want to focus on the 'how'.
The core of this tool is just described in natural language. All of the most complicated pieces, including:
task generation
code generation
feedback and critique
and more. At no point did the creators need to know how to solve these problems. They simply provided some examples and then asked nicely.
Going back to Part 1, programming languages are about making tasks easier. Each higher level programming language bridges the gap between how we think about a problem and how we describe it to a computer.
That gap has slowly closed. And with LLMs, I think that gap is almost 0. That in turn means the barrier to programming has dropped significantly.
One of the most enduring critiques of Silicon Valley is that 20-something tech founders keep solving problems 20-something tech founders have. (Do we really need another food delivery app?) More seriously, because developers create their own tools, they experience a level of operational efficiency that is pretty unfamiliar to the vast majority of workers. In a world where everyone can program and automate aspects of their lives, we should see a massive increase in diversity of tools, products, and (in the long run) efficiency. And of course, more efficient outcomes begets more investment in tools and products, creating a virtuous cycle.