
LLMs are Programming Languages: A review of Voyager (Part 1)
Understanding Programming by Prompt

This is Part 1 of a two part series. Part 2 can be found here.
I want to review this new-ish ML paper, Voyager: An Open-Ended Embodied Agent with Large Language Models. But in order to really understand Voyager, and why Voyager is so fucking cool, I need to go fairly high level.
What is programming?
For me, it starts at the definition of a computer program. I actually went to a dictionary for this one, just to make sure I was being really exact.
A computer program is a set of instructions that a computer can execute.
Computers understand bytecode. Bytecode is a small subset of commands that perform basic mathematical operations and manipulate the storage of numbers. Bytecode is pretty awful to work with, because it looks something like this:
B8 04 00 00 00 BB 01 00 00 00 B9 [address of hello] BA 0D 00 00 00 CD 80 B8 01 00 00 00 31 DB CD 80But back in the day (maybe the 40s or 50s) computer programmers actually programmed in bytecode. This meant two things: one, being a computer programmer was an exercise in frustration; two, very very few people could be programmers.
Over time, people developed programming languages. These languages are generally easier to read than bytecode, but through a 'compilation' step, they can turn into bytecode. And, in the year 2023, we actually have programming languages that turn into other programming languages, which then turn into bytecode.

Generally speaking, each layer in this stack is easier to work with, or better at solving some set of problems, than the layer below. There's no such thing as a free lunch of course. The tradeoff with using easier to understand languages in the stack is that each subsequent layer will run slower than the one above it. But in a world where computers are really fast and developer time is really expensive, this is a totally worthwhile tradeoff to make.
So just to go through and really build some intuition, you start with bytecode:
B8 04 00 00 00 BB 01 00 00 00 B9 [address of hello] BA 0D 00 00 00 CD 80 B8 01 00 00 00 31 DB CD 80Which as mentioned is terrible and bad. Then you have assembly,
section .data
hello db 'Hello, World!',0
section .text
global _start
_start:
; write syscall
mov eax, 4
mov ebx, 1
mov ecx, hello
mov edx, 13
int 0x80
; exit syscall
mov eax, 1
xor ebx, ebx
int 0x80Which starts to actually look like a real programming language. Like bytecode, assembly is mostly concerned with moving and manipulating numbers, but at least you don't have to write hexadecimal values to do that.
After assembly, you get C:
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}Which is actually still very much in use. Unlike assembly, C gives access to higher level data types, structures, functions…basically everything we associate with a modern language. And the C compiler of course compiles into assembly, which compiles into bytecode.
Pretty soon after C you get C++
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}Which is basically a slightly more memory safe version of C. And interestingly the very first C++ compilers actually just output C directly, which of course compiles into assembly which compiles into bytecode.
And eventually we end up with Javascript,
console.log("Hello, World!");which runs in everyone's web browsers. And if you're using Chrome, then every time you open a website you're actually running javascript in the C++ V8 engine, which of course compiles into C, which compiles into assembly which compiles into bytecode.
And you can do more than this! At SOOT, we use a language called Typescript,
console.log("Hello, World!");
// OR
function sayHello(): void {
console.log("Hello, World!");
}
sayHello();Which is a lot like Javascript but it introduces type safety, so it's a bit easier to write. Typescript compiles directly into Javascript, which runs in C++, which compiles down to bytecode.
And if you don't like flavors of javascript you can use something called WASM, which I won't get into here, but the funny thing about WASM is that you can then compile other languages into WASM, including C!
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}So now we have C compiled into WASM compiling into Javascript, running in C++, which compiles back into C, eventually compiling down through the stack to bytecode. All of this is of course very silly, but frankly it's amazing that it's even possible.
Why am I going through all of this? At each stage in this process, we're making programming languages easier and more expressive. More people can write javascript than can write assembly, because the mental gap between an idea in your head and an idea in javascript is smaller than the gap between an idea in your head and an idea in assembly.
Let's talk about LLMs
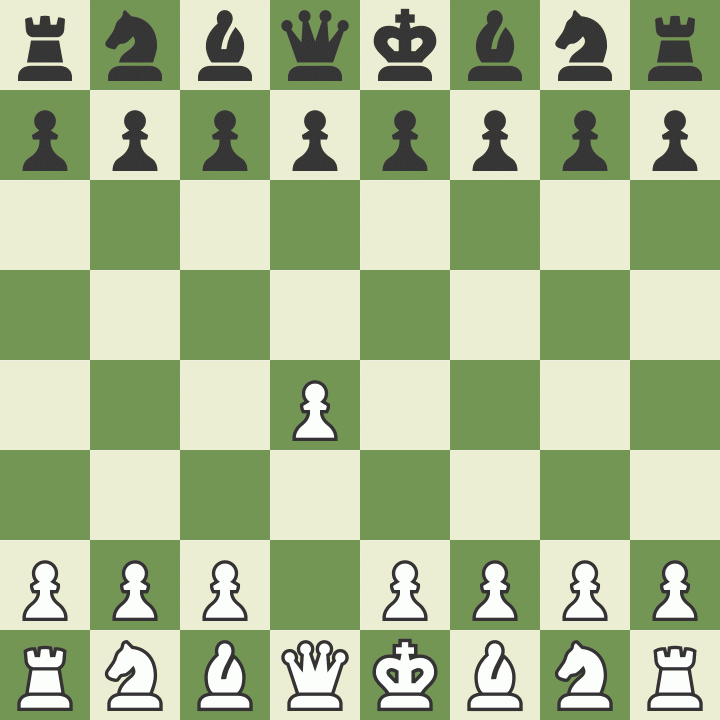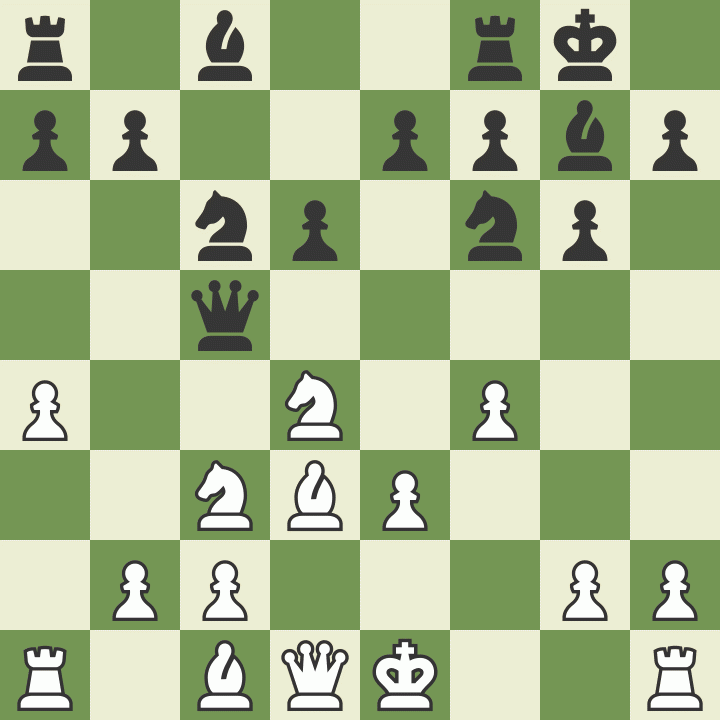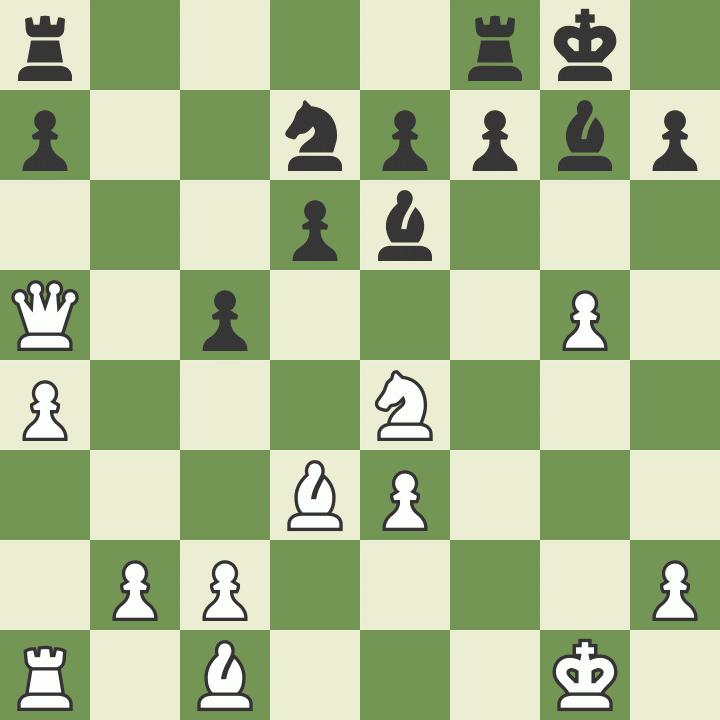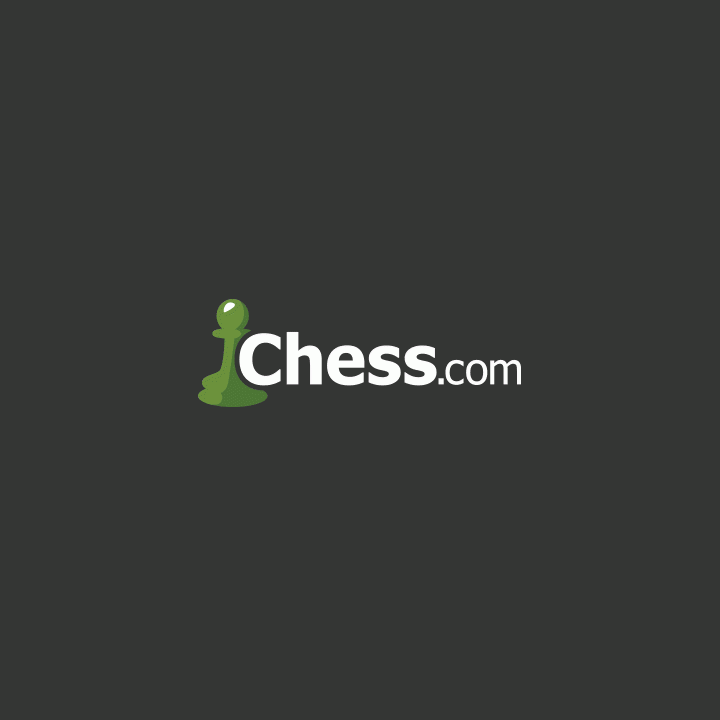
LLMs (large language models) take in text and try to predict the next word in a sequence. It turns out that a great many problems can be phrased as inputting and outputting text, so LLMs end up acting as pretty generic problem solvers. For example, if you put chess notation into GPT, it spits out more chess notation. This allows you to 'play chess' against an LLM, which on it's own is absolutely fascinating — after all, LLMs don't have any concept of 2D space, much less the rules of chess.
More modern LLMs, such as ChatGPT, are specifically trained to respond in a QA format. And this allows us to do a pretty wide range of interesting things.
About three years ago, when I first got to play with GPT3, I made a prediction: we were going to see the rise of a new programming paradigm, "Programming by Prompt", in which users would be able to automate tasks in English. I guessed we would see the full maturity of Programming by Prompt in 2025; turns out, I was a bit too pessimistic. I think LLMs as we currently know them are already a higher level programming language.
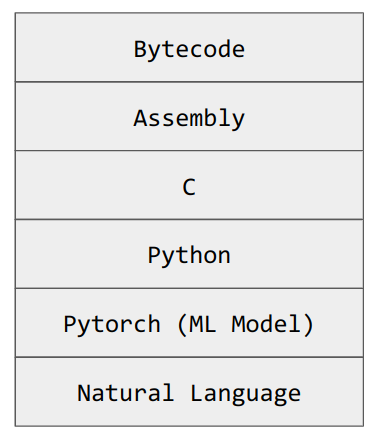
Above, I wrote out a basic 'hello world' script in a few different languages. This is how you might program hello world in LLM.

The LLM will take natural language (i.e. English), compile it into a Pytorch representation, which gets compiled into Python, which calls out to C, which (say it with me) compiles into assembly which compiles into bytecode. LLMs allow us to make English directly interpretable to a computer.
And of course you can do more complicated things than hello world. For example, if I wanted to calculate a fibonnaci sequence, I might program something like the following:

And as expected the LLM does the right thing:

When I say something like "Programming in Python is easier than programming in C", what I generally mean is "it takes less effort to express ideas in and understand the former rather than the latter". LLMs are a natural extension of this concept. Instead of writing code in a programming language, you write code in English. The gap between idea and expression drops to 0.
Describing Problems Instead of Solutions
There is one huge difference between LLM programming and 'regular' programming. So far, all of the other programming languages that we've spoken about — C, Python, even Assembly — require the developer to know what they are programming. A program is, in some ways, a description of the programmer's mental state. Going back to the fibonnaci example above, if I want to program that sequence in Python I need to actually know the formal solution for the fibonnaci sequence.
Not so with LLMs. Check this out.


The amazing thing about LLMs is that the developer does not need to know the solution. Instead, the developer just needs to be able to describe the question, and provide examples of right answers. The LLM 'compiler' does the rest. Unlike other programming languages, LLMs can solve problems that are inherently fuzzy, that do not have any right answers. And, as it turns out, there are a lot of really generic problems where it's easy to come up with a correct answer, but hard to come up with a generic, formal solution.
IMO this is a paradigm shift in what it means to program. LLM programming allows us to automate some really fuzzy tasks while creating agents that feel really generalizable.
But, to play devil's advocate, the LLM has likely seen the fibonacci sequence dozens of times in its training data. It's not that crazy for it to recognize and calculate fibonacci, right? Stay tuned for part 2, where I dive into a much more interesting example of programming by prompt — the Voyager paper.