
Tech Things: Inference Time Compute, Deepseek R1, and the arrival of the Chinese Model

When I was in highschool, I took the American Math Competition 12 exam, commonly known as AMC 12. The exam has 25 questions, multiple choice. The questions are challenging, but not impossible. Given enough time, I suspect most of the seniors at my fancy prep school would be able to do quite well on it. The problem is that you only had 75 minutes to complete the exam. 3 minutes per question. It was, obviously, not enough. The time limit did a good job of filtering for folks who really knew how to get to the right insight quickly. And rightly so — the AMC 12 exam is the qualifying exam to compete in the International Math Olympiad, among other things. Still, the time limit made the test artificially more difficult.
I never did particularly well at the AMC exams. I don't, like, enjoy math very much — that's why I went into AI! But also, I was frustrated by the time limits, and the artificial difficulty. In the real world, you might spend a lot of time thinking about a problem. And, in fact, it's almost tautologically true that the really interesting problems worth solving take a lot of time to think about.1
One thing that's weird about a lot of AI models is that we expect them to behave like 'general intelligence' but do not give them time to actually reason through a problem. Many LLMs are running the AMC on 'artificially hard' mode. Except, they don't have 3 minutes to respond, they have to respond instantly. Part of why that's the case is because for a while, it was not even obvious what it meant for an LLM to 'take more time'. If you give a human a test — like the AMC — they can tell you "hey I need another minute or two to solve this problem" and do the equivalent of spending more CPU cycles on it, or whatever. More generally, a human can decide how long they need to chew on a problem before committing to an answer. LLMs can't really do that. The LLM has a fixed compute budget, determined by the size of the model and the context window (the number of tokens it can 'look at' at one time). Anything that requires more reasoning than that isn't going to work.
OpenAI has been chewing on this problem for a while, and came up with a concept they call 'inference time compute'.
The earliest version of this was simply asking the LLM to show its work. Researchers discovered that if you asked an LLM to write out, step by step, how it solved a problem, accuracy went up.

It was theorized that this was kinda sorta equivalent to giving the LLM 'more time' to solve the problem. More advanced inference time compute solutions include things like:
Having an LLM output its intermediate thinking to a scratchpad, and having a different LLM pick up the intermediate output;
Giving the LLM special 'reasoning tokens' that allow it to go back and edit or change things it previously said;
Running multiple 'reasoning threads' in parallel and then choosing the one that is most likely to get to the best answer;
Running multiple ‘experts’ in parallel and then choosing the answer that the majority of them reach;
Training some reinforcement learning process on the reasoning output of an LLM to optimize for ‘better’ reasoning.
The core idea behind all of these things is to dynamically increase the amount of time and computer resources it takes for the LLM to answer the question, in exchange for accuracy. Harder questions get more compute, as determined by the LLM. This technology has been behind OpenAI's O-series models, including the latest public o1 model and the very-impressive-but-still-private o3 model (discussed here).
In case you haven't noticed, OpenAI and Google (and Anthropic and Meta) are in a tiny bit of an arms race right now. They are trying to capture the "LLM infrastructure layer", and are working really hard to do so because there are really strong winner take all market dynamics. I've written about this in the past in when I discussed how the LLM market was similar to search:
Normally, when an upstart company wants to take a bite out of a big established market, they go low on price. This is especially true in a setting where the underlying product isn't sticky. All things being equal, consumers will go for the best product along some cost/value curve. Some consumers may pay more for premium services; others less for cheaper services. That segmentation allows for competition among many smaller players.
But search is free. There is no price competition, because in the status quo consumers aren't paying anything. So the curve collapses into a line, the only thing that matters is whichever search engine is the best one.
This leads to massive economies of scale and winner-take-all market dynamics. Google is the most popular search engine because it's the biggest and best one, which gives it all the money to continue being the biggest and best one. If a competitor managed to become bigger and better, it may flip the market, but good luck doing that out of nowhere.
Going back to LLMs, I think you see roughly the same market dynamics. LLMs are pretty easy to make, lots of people know how to do it — you learn how in any CS program worth a damn. But there are massive economies of scale (GPUs, data access) that make it hard for newcomers to compete, and using an LLM is effectively free so consumers have no stickiness and will always go for the best option. You may eventually see one or two niche LLM providers, like our LexusNexus above. But for the average person these don't matter at all; the big money is in becoming the LLM layer of the Internet.
And, as expected, there's only a handful of LLMs that matter. There's a Chinese one and a European one, both backed by state interests. And there's Google, Anthropic, and OpenAI all jockeying for the critical "foundation layer" spot.
The economics of LLMs means that it is critical for these players to have the best models. There's no room for second place.
So even though OpenAI is called OpenAI, they have been decidedly tight-lipped about how their inference time compute stuff actually works, likely because of the intense competition. I don't really blame them. I've heard that Google has been aggressively poaching anyone and everyone with an OpenAI offer, giving L4-equivalent engineers high-6 / low-7 figure salaries to keep them away from the competition. The teeth are out, the kumbaya "let's all share what we're working on for the good of humanity" stuff is long gone.
Because of the strong winner-take-all market dynamics, there have only been a handful of players actually capable of operating in the LLM training layer. And if you aren't in the AI space, you'd be forgiven for thinking that the list of major players starts and ends with Google and OpenAI.
But remember what I said about that Chinese model? Right, well…

3 days ago, a Chinese company called Deepseek released a model called Deepseek R1 (paper here). The model outperforms all of the Meta models and Anthropic models. It also outperforms the supposedly super-secret OpenAI O1 model. And, just to add insult to injury, it's totally open source and free to use. Yes, there is a deep irony in a Chinese company fulfilling OpenAI's founding mission better than OpenAI.
To be clear, the fact that Deepseek exists isn’t really that significant. Everyone always knew there was going to be a big Chinese model. The country is not afraid to wall off it’s populace from the West; it was never going to allow LLMs that are happy to tell people about Tienanmen Square and Winnie the Poo and Taiwan. So when the first Chinese LLMs came on the market, everyone was like, “Yea, whatever”. The first batch, the Qwen models from Alibaba, were, like, fine.
Even though I expected a set of LLMs to arise thanks to protectionism and state-interest, I (and everyone else) assumed those models were just going to be worse than the US ones. This is how technical development has always been, after all. Google Search is good, Baidu is eh, and if you can use Google over Baidu you do. Amazon is good, Alibaba is eh, and if you can use Amazon over Alibaba you do. Facebook is good, Tiktok is eh, and if you can…no wait that doesn't work does it?
Anyway, the larger point is that no one really thought the Chinese models were a threat. Sure, people would talk about how the Chinese government was a threat, but it was always in a hypothetical way, mostly used to justify infinite capitalist investment without any corresponding concerns about AI safety or alignment.2 I don't think most people actually thought that a Chinese company would come out and deploy a model that is simply better than what we have in the states.
Clearly we didn't actually learn anything from TikTok.

Deepseek isn’t, like, kicking O1’s ass or anything. But the prevailing understanding in the tech world is that this shouldn’t be possible at all. The real Chinese Model has arrived, and it’s a force to be reckoned with.
The most interesting thing about Deepseek is how much they seem able to do with so little investment and compute. The company that created Deepseek isn't even an AI company. It's a quant hedgefund that just happened to have a lot of GPUs lying around and decided to get in the game.
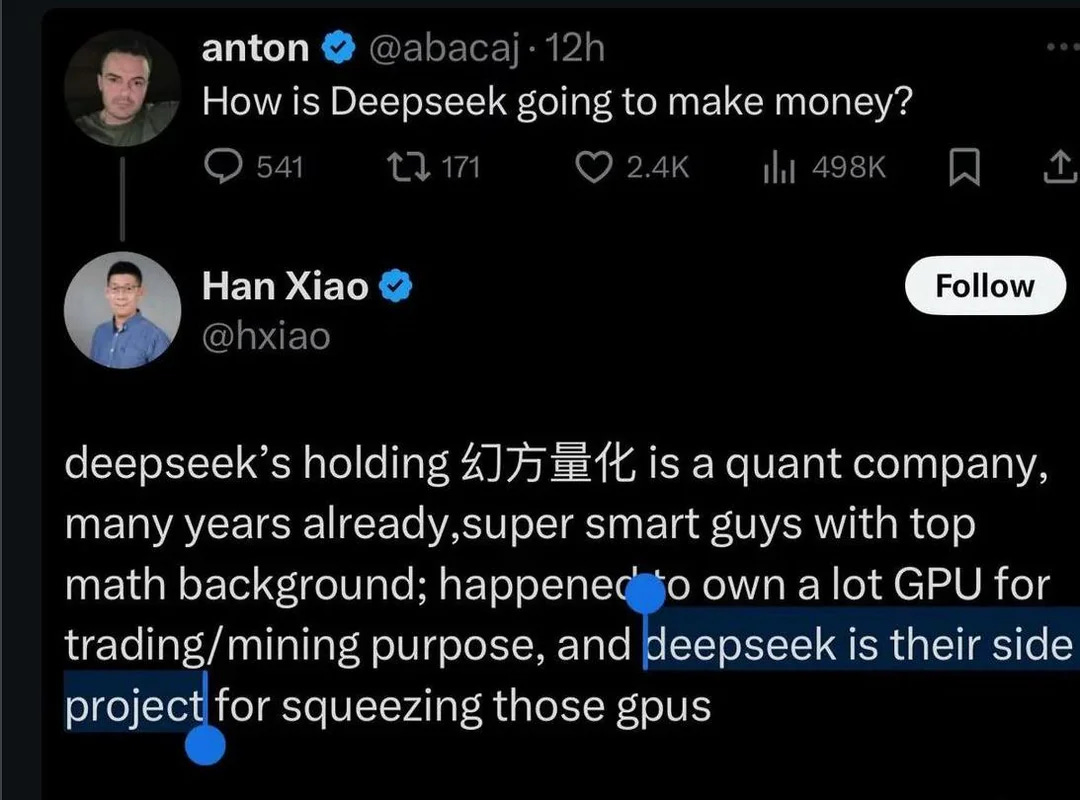
A side project.
We don't know exactly how many GPU dollars were spent to train Deepseek R1, but the consensus is "a lot less than whatever OpenAI spent with their massive supercluster".3 The output is certainly small enough to be something folks can run on consumer hardware. That in turn means the pricing of Deepseek is much better than O1. And remember what I said earlier: there are massive centralization effects and winner-take-all dynamics in the LLM infrastructure market. If Deepseek is better than O1 for roughly the same or better pricing, no one will use O1. LLM developers have already started switching to the cheaper model — most of their use cases don’t really require a detailed explanation of Sino-Taiwanese relations anyway.
So now the question on everyone's mind is: is Deepseek's team just absolutely amazing at what they do (cracked, as the kids say), and could they pull off miracles if they were as well capitalized as OpenAI? Or is OpenAI hiding something in their super cluster that they haven't shared with the world yet?
I think the last year has been one of a lot of existential angst among software engineers generally and AI engineers specifically. I've heard L6 and L7 engineers at Google talk about trying to find new skills because they think AI is going to take their jobs within a year or two. Now there's another layer on top of everything else. Maybe eventually the AI will take your job, but it's going to be outsourced to a Chinese AI engineer first!
Otherwise, someone probably would have solved the problem already!
"Slowing down development to focus on AI alignment doesn't actually matter because the Chinese will do it anyway and be a lot less scrupulous" — many people in the ACX comments. In the college parliamentary debate scene, this was called “China-baiting”, and it was generally derided as a stupid argument. Enough that you could get up and say “stop China-baiting” and that would be the end of the discussion.
We have a bit more information about the previous Deepseek model, Deepseek v3, which is comparable to GPT-4o. That model was released about a month ago and cost about $5.5M to train. That’s not a small amount, but it’s way less than what OpenAI spent. Sam Altman claimed that GPT 4 cost over $100M to train. Relatedly, he’s been a bit salty on Twitter.