
Tech Things: Genie’s Lamp, OpenAI can't make graphs, Anthropic is also here, Where is everyone else?
It was a busy week in the AI world.

Genie 3
The goal of AGI is to make programs that can do lots of things. Unfortunately, it's not all that easy to program “do lots of things” into a computer. Like, if you're writing python, there's no `import everything` library – you have to somehow teach your program a bunch of different tasks and skills. Naively, you could spend a lot of time hand coding every possible scenario that may occur – some gigantic switch statement that has a unique handler for every possible input. But this is obviously going to take too long and is extremely inefficient and really only theoretically possible.
So the watchwords of AGI are compression and generalization. You want to make a program that is pretty small in terms of compute and memory and so on, but has a lot of abilities that allow it to cover a very large ‘action space.’1
One way to teach your program how to generalize across things is by using deep learning. At a high level, you can show a deep neural network terabytes of data, and it will learn how to represent that data in a compressed form. The big large language models take in ~all of the text ever written, and are maybe a few tens-of-gigabytes in size,2 and yet seem to be able to replicate much of the training data. Perhaps the most surprising revelation of the last few years is that in addition to getting really good at spitting out realistic looking text, these LLMs also picked up more generic skills. The most evocative example of this for me was realizing that the original GPT-3 models – the ones that preceded ChatGPT, that had no ‘post training’ or ‘instruction tuning’ – could play a decent game of chess, even though the model surely didn't understand chess, and probably didn't really understand 2D grids. And since that moment back in 2020, it has become extremely obvious that these things can do quite a fair bit beyond just mimicking text.
A lot of AI research these days is basically exclusively about how to make large language models better. Naturally, some people focus on “large” – if you make the model bigger, it can get better! But some people also focus on “language” – LLMs are only compressing text, but what if it compressed more kinds of data? A model that could represent text and images is probably better than one that can only represent text. And a model that could represent text and images and video is probably better than one that can only represent text and images.
If you assume that model representation capacity is directly tied to usefulness, you'll eventually reach a conclusion that looks something like this: “a model that can accurately represent the entire world is going to be pretty damn useful.” Imagine asking a model a question like “what's the weather in Tibet” and instead of doing something lame like check weather.com, it does something awesome like stimulate Tibet exactly so that it can tell you the weather based on the simulation. And giving a robot the ability to represent the world may allow it to do things like plan complex movements, navigate environments, and otherwise interact with real world environments. After all, this is approximately how humans work. In order to pick up my mug of not-coffee, I have to have an internal representation of my hand, the table, the mug, where my arm is going to go, how my hand is going to grip, what gravity is, what object-corporeality is, etc. etc. More mundanely, world models will probably allow people to make, like, better, more realistic AI generated Tiktoks that don't turn into spaghetti after a few minutes (and I'm sure nothing bad will come of that).
These “World Models” are considered a pretty long shot frontier in the AI world. Hopefully for obvious reasons — simulating an entire world for extended periods of time with any kind of accuracy is really hard! You need mountains and mountains of data, most of it video. And as a result, there aren't a lot of people who are really even trying in this space.34 But you know who has a mountain of video data?

About 3 days ago, Google announced Genie 3. Genie stands for Generative Interactive Environments. The best way to understand Genie is by analogy. GPT and Gemini let you create text descriptions of a time and place. And Veo and Sora let you turn text descriptions into video. Genie lets you take a text description into a video game, a space that you can, at least primitively, interact with.
It is kind of incredible? The reason Genie gets the headliner title over GPT-5 (below) is that Genie is really, truly something different.
Now, you can only really interact with a world Genie creates for a few minutes. But that is a massive step up from where we were previously. And it points to the future. Coherence over long context windows used to be a very difficult problem for language models too – if you've been reading my ml paper review series you'll know that a solid part of the last 10 years of AI research has been motivated in part by this very problem. Last I checked we did a pretty good job with it; similar progress is possible for world models. More importantly, Genie 3 is now at a point where you can start using it for a wide range of other tasks, including training other models. You don't need to drive millions of miles in a Waymo if you can artificially create long-tail distribution events and train on those!
For folks who are interested in the more technical aspects of how this thing works, you're a bit out of luck. Publishing at Google is a bit weird these days. Any research papers that get written up first go into an internal pool. If any of the Gemini product teams want to productionize research out of that pool, the paper doesn't get published. As a result, I suspect we won't see papers for Genie 3 (or even its predecessor, Genie 2) any time soon. Here's the Genie 1 paper though. I'll try and review it soon.
GPT-5


The big story about GPT-5 is about what it isn't.
It isn't a world-changing super-intelligent insane-step-up on the intelligence ladder. It isn't God. It isn't close to God.
Now, if you've been reading my blog for any length of time, you'll know that I didn't really ever suspect OpenAI would be the one to stumble upon God in the machine, even though that is in some sense their explicit purpose. I tend to think Google is going to do it, mostly by accident, and will probably also end up sitting on the research for too long until OpenAI-2-electric-boogaloo comes around and tries to eat their lunch, again.
But still. There was so much hype around GPT-5, and now all that hype has deflated.
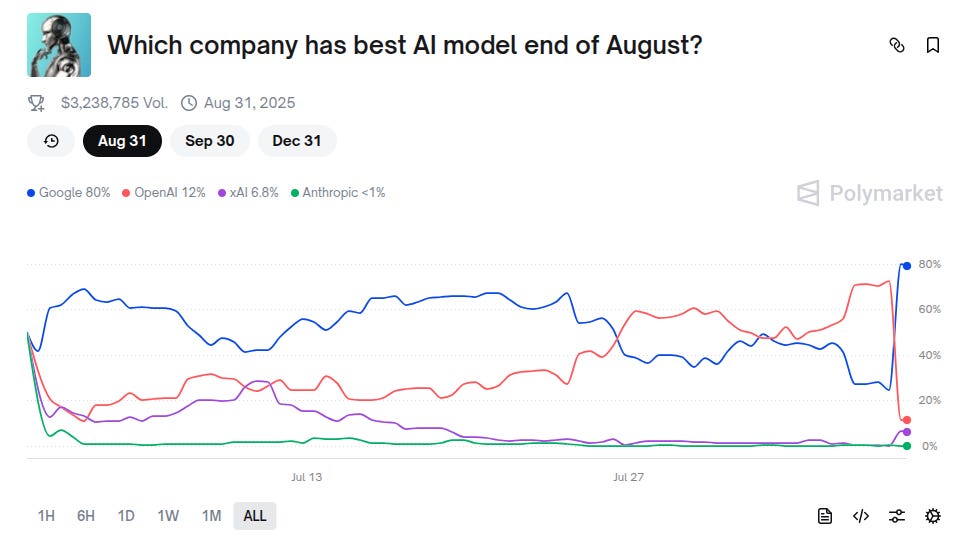
Starting about a year ago, people began to complain that AI had hit a wall because GPT-5 was not yet released. Some folks (cough Gary cough) were even starting to make claims like "GPT-4 is the best AI we're ever going to get". At the time, I pushed back, blaming our short attention spans and need for immediate gratification:
But is AI stagnating?
There is a strict sense in which consumer AI may not feel like it's growing at the same rate as it did from 2020 to 2023. That period was a particularly magic time where we had a surplus of chips that we had to catch up to. Like a gas expanding to fill a volume, our chip utilization has caught up, so releases may not be at such a rapid clip.
Some of the problem here is that consumers are just getting impatient. The first version of GPT3 was published in May, 2020. GPT4 was launched in March, 2023. That’s 34 months. It’s only been ~20 months since GPT4 was released, there’s a bit more time to go before OpenAI starts ‘falling behind schedule’. We haven’t had the capability to even create large enough GPU clusters until recently. And it is also plausible that the release of stronger LLMs tracks more to self driving cars than to iPhones. The hypecycle for self driving cars was at its peak around 2014-2015. Even though the technology wasn’t quite consumer ready by then, the estimated ‘release date’ was still within only a few short years. In 2024 there are readily available self driving cars in several cities. From a research perspective, the folks saying that self driving cars would be ready within a few years of 2014 were more right than those saying it would never be ready at all.
As for the people who are arguing that AI is obviously dead and the whole field was doomed to failure because it's "just statistics" or "just linear algebra", idk, this feels a lot like shifting goal posts. Standard LLMs are exposed to way less data than the average human baby, the fact that they can do anything at all is a miracle, the fact that they can regularly pass competence tests like the SAT or the Bar should be endlessly awe inspiring. For some reason people keep wondering when we'll have AGI, even though it's literally here and accessible through a web browser. In any case, the cope isn't going to stop the AI from taking everyone's jobs (mine included).
I stand by basically all of what I said. But I also have to eat some of the intent behind my words here. With GPT-5, I was clearly expecting something closer to the step function increase in functionality that we saw between GPT-3 and 4. Unfortunately, we really did hit a serious industry-wide asymptote in our ability to get more out of next-token-prediction. In retrospect, I think GPT-5 was always going to be disappointing. I'm sympathetic to the OpenAI team here, people were expecting literal miracles. But also, Sam definitely played a role in building up hype — and, as a result, increased the mountain OpenAI would have to eventually summit.

So what is GPT-5? It's basically GPT-4, but better. It's still early, but it seems to be significantly more consistent, which is no small feat. OpenAI already has most of the consumer brand recognition; there are many people for whom "LLM" and "AI" are synonymous with "ChatGPT". But I suspect that those of us who swap models frequently will begin to use OpenAI as a daily driver again.
This shouldn't be understated. GPT has not been a part of my daily life at all since approximately January of this year, when I fully switched to Claude. And when I switched over to using Gemini for code and Claude for everything else, I took the extra step of uninstalling the ChatGPT app from my phone. More generally, I think there's been a bit of a 'vibe shift' in the Bay and among AI researchers and practitioners. People are starting to realize the sheer weight of Google's TPU farms, while OpenAI talent is getting siphoned off by liquid billion-dollar offers on one side (e.g. Meta) and even more ideological startups on the other (e.g. Safe Superintelligence, whatever Mira Murati is up to). Friends who are way more plugged in than I am5 describe an anti-OpenAI "coalition" forming, with many of the folks who had been burned by Sam's aggressive commercialization lining up to give the company a black eye. If you were more social-graph-minded, you may read a lot into Alexandr Wang — Sam Altman's ex-roommate and close confidant — leaving Scale.AI for Meta.
In this context, being the best in class is really important. Important people are losing faith, and those important people talk to other important people who have money. OpenAI needs to justify their extremely high valuation and their capex burn. If I’m right that LLMs are a winner-take-all game, OpenAI has to position itself as the winner.
They may have a tough time doing so though if they can't get their graphs straight. I mean what the hell are these?
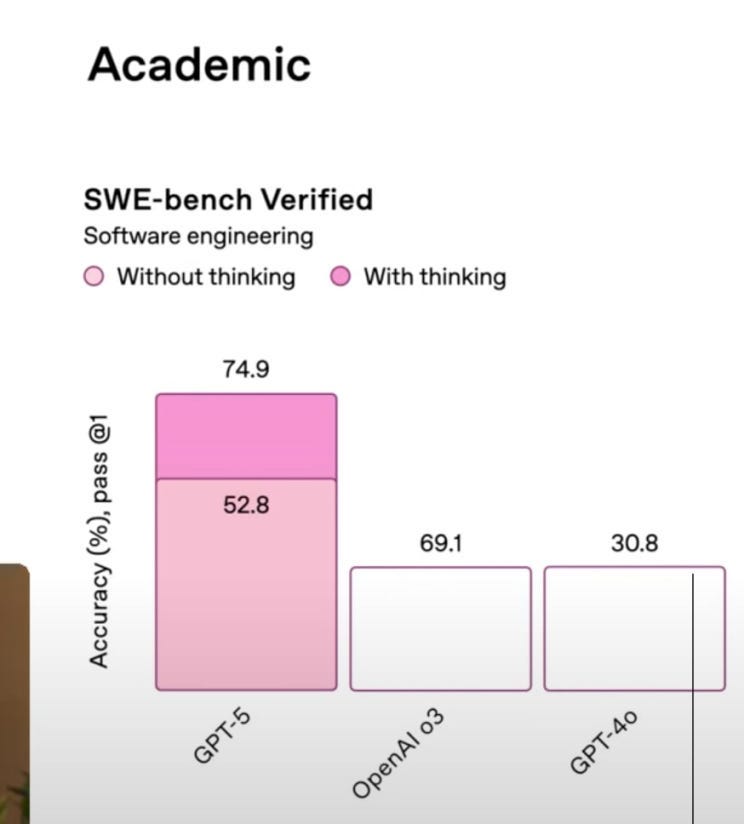
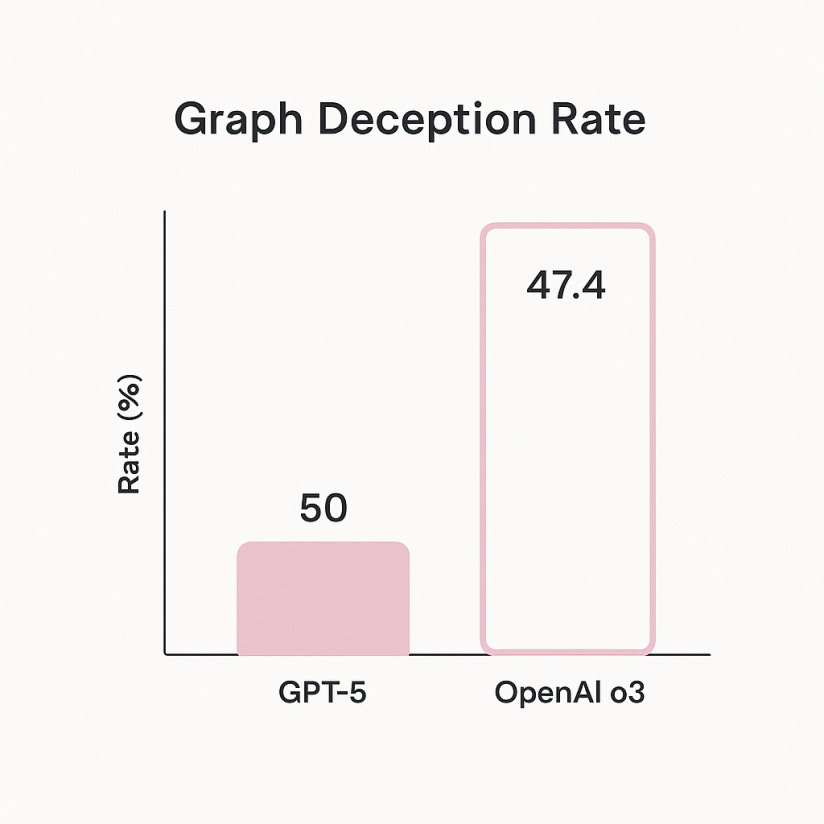
Ok, ok, that's great and all. But what is GPT-5? How does it work? Well, OpenAI isn't exactly going to release a public research paper about their latest and greatest. But we can go off the model card.
GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent…In the near future, we plan to integrate these capabilities into a single model.
In other words, GPT-5 is a bunch of smaller models in a trenchcoat. I've long believed that many of the consumer-facing web chat interfaces were powered by many models instead of one really big model. It is simply more cost effective. I've written in the past about 'the bitter lesson', which can roughly be summarized as "scaling compute and data will lead to more long term progress than hand crafted heuristics and rules". But a natural corollary to the bitter lesson is that, for a fixed budget, human crafted systems are often more efficient. So here. Unfortunately, there just isn't that much additional information for how it works beyond that.
Anthropic is also here
Even though Anthropic already had their big Claude 4 release a few months ago, they didn't want to feel left out, so they released Claude Opus 4.1. Rather appropriately titled, it really is just a slightly better version of Opus 4. I'll take it.
Claude hasn't really been at the top of any of the leaderboards for a while. And yet I and many very technical and AI-savvy people continue to use it. This is…somewhat odd? Why do I purposely use a worse model?
I think the short answer is that it's not worse. Teaching to the test is as much a problem in AI as it is in education. I mean this is standard Goodhart's law stuff — the tests are meant to be proxies for competence, not targets. Even though Claude doesn't top leaderboards, it feels better to use. And any other gaps in model quality are simply papered over by Anthropic's focus on the user experience. As a developer, Claude is just way better. The artifact system is great, and the claude code CLI is a seamless experience.
A friend of mine described Anthropic as the Apple to OpenAI's Microsoft. And, like, yea, I see it. I guess Google is still just Google in this metaphor, idk.
Where is everyone else?
I feel like every other month I hear about some random famous tech person raising a bajillion dollars to start an AI company. John Carmack raised $20M in 2022. Ilya raised $1b in 2024, and then another $2b a few months ago. Mira Murati raised $2b in July.
Ilya's company is valued at $32b. As far as I can tell, the only thing it has produced is the 370 words on its website. That is $86,486,486.49 per word. And 148 of those words are about Daniel Gross stepping away from the company. At least Ilya has a website, Carmack has literally disappeared.

What is going on! Where are all of these people? What happened to the billions of dollars? Do they realize how many taco bell burritos you can buy with a billion dollars? Where are these people??? If any of you know what is going on at any of these places, please tell me.
This is not that crazy — the human brain is quite small and runs on shockingly few calories, after all.
I'm talking about just the text models here — Llama 4 Maverick clocks in at a whopping ~800GB, but it can also handle images. Google's Gemma models are much smaller, at most 20-something GB.
With apologies to the many PhDs who are in fact trying in this space! I deeply respect all of you, but when I say 'trying' I mean 'throwing hundreds of millions of dollars at the problem', which is basically the new standard in AI.
Off the top of my head, Fei-Fei Li's company / lab explicitly uses the world model terminology, and OpenAI has published papers that discuss how video-generative model Sora is like a world model, but it's really just those two and Google.
you know who you are if you're reading this <3
Carmack gave a tech talk this summer about some of what they've been working on https://youtu.be/iz9lUMSQBfY?
A summary of their focus is: fundamental research, understanding virtual worlds, Atari games as benchmarks, transfer learning
👍