

Tech Things: Python Christmas Gift, Tech Layoffs, Amazon Spam
Tech Things: Python Christmas Gift, Tech Layoffs, Amazon Spam

Python is getting faster, just in time
For those of you who get the pun in the title, I apologize. For those of you who don't, let me explain a thing or two about compilers1 (and then let me apologize).
At a very high level, computers understand something called 'machine code'. Machine code looks something like this:
b8 21 0a 00 00 #moving "!\n" into eax
a3 0c 10 00 06 #moving eax into first memory location
b8 6f 72 6c 64 #moving "orld" into eax
a3 08 10 00 06 #moving eax into next memory location
b8 6f 2c 20 57 #moving "o, W" into eax
a3 04 10 00 06 #moving eax into next memory location
b8 48 65 6c 6c #moving "Hell" into eax
a3 00 10 00 06 #moving eax into next memory location
b9 00 10 00 06 #moving pointer to start of memory location into ecx
ba 10 00 00 00 #moving string size into edx
bb 01 00 00 00 #moving "stdout" number to ebx
b8 04 00 00 00 #moving "print out" syscall number to eax
cd 80 #calling the linux kernel to execute our print to stdout
b8 01 00 00 00 #moving "sys_exit" call number to eax
cd 80 #executing it via linux sys_callThis is basically incomprehensible, but a long time ago early computer scientists actually wrote programs like this. Which, of course, sucked. Also, different hardware had different machine code that they could read. So if you had an Intel chip, you had to use Intel machine code, if you had an ARM chip you had to use ARM machine code. Which, of course, also sucked. And if you wanted code to go across different chips you had to either limit yourself to things that all the chips could understand or write the same code more than once. Which, you guessed it, sucked.
But it was fast. Like really really fast.
Still, eventually people got fed up with this state of things and invented compilers and, with compilers, programming languages. The basic idea is that you write something that's more readable to a human, like:
#include <stdio.h>
int main() {
// printf() displays the string inside quotation
printf("Hello, World!");
return 0;
}And then you let a machine convert all the words you wrote into machine code. The machine looks up each word or set of words that you write in a big table that maps those words to machine code instructions. It then strings together and outputs a file for whatever chip you are trying to run on. Machines are really good at automatically doing the same thing over and over again, and people were able to make compilers that were pretty effective at turning not-machine-code into machine code by building in all sorts of smart optimizations. The trade off is that the "compiled" machine code was a bit slower than hand written machine code. But, importantly, it didn't suck as much to write. And it was faster to write, and developers are more expensive than computers.
For a long time, the "write code" step and the "compile code" step and the "run code" step were all different things. If you've ever written C or Java, you know that you have to first "compile" the code into an executable, and then you could run it. If you write a lot of code, it can take a long time to compile — without any extensions, Linux takes about 5 minutes to compile end to end. Compiled code also generally has stricter requirements — you have to care a lot about syntax and variable types and memory handling and so on. This all isn't quite as bad as writing machine code directly, but it does in fact still suck.
Eventually people got fed up with this, too, and came up with interpreted languages. Like Python! The basic idea is that you write some code that looks like this:
print("hello world")And that code is fed to a Python interpreter, like Python3.8. The interpreter will read each line sequentially and run it immediately, without looking at the rest of the code. Effectively it combines the compile time and runtime steps.
Interpreted code is great because it removes many restrictions. You don't have to worry at all about hardware. You can inject code as the code is running, or inspect variables and other state directly. Obviously, you don't have to wait to run your code by compiling it first.
But interpreters are quite slow, because they do two translation steps. First, they have to take your code and convert it to a language the interpreter understands. For folks who are interested, this intermediate is called "bytecode". (you might wonder why interpreters can't compile directly to machine code. The answer is that it's too hard — there are too many devices, instruction sets, and so on to go directly from the highest level python to the lowest level machine code). Second, they take the interpreter language and turn it into machine code. Each bytecode instruction might translate to dozens of machine code instructions, and they basically never change.
The interpreter does these two steps every time it encounters a line of code, even if it's the exact same code. In other words, a ton of interpreter time is spent converting the same exact bytecodes to machine code over and over. Combined with the lack of compiler optimization, and you get code that's 100s of times slower and more memory intensive than the same code in C.
This sounds terrible, but actually for the most part, devs were pretty happy with this. If you want to write something fast, use C. If you don't care and want to be happy, use Python.
Unless, of course, you're one of the guys who actually maintains Python-the-language. If you're one of those guys, you might be kinda annoyed that everyone who writes C is constantly shitting on your language for how slow it is. Also, like, if you enjoy writing Python (or don't know anything else) probably you want Python to be better.
And finally, we get to the joke that started this whole thing. Over Christmas, Python core dev Brandt Bucher sent out a big change to the Python interpreter.
This is a cool change. Partially because it adds a Just in Time compiler (JIT) to Python. But mostly because the whole change is described entirely in Christmas verse:
'Twas the night before Christmas, when all through the code
Not a core dev was merging, not even Guido;
The CI was spun on the PRs with care
In hopes that green check-markings soon would be there;
The buildbots were nestled all snug under desks,
Even PPC64 AIX;
Doc-writers, triage team, the Council of Steering,
Had just stashed every change and stopped engineering,
When in the "PRs" tab arose such a clatter,
They opened GitHub to see what was the matter.
Away to CPython they flew like a flash,
Towards sounds of PROT_EXEC and __builtin___clear_cache.
First LLVM was downloaded, unzipped
Then the Actions were running a strange new build script,
When something appeared, they were stopped in their tracks,
jit_stencils.h, generated from hacks,
With their spines all a-shiver, they muttered "Oh, shit...",
They knew in a moment it must be a JIT.
... (there's 4 more verses of this, I'm in awe)A JIT is a middle ground between a compiler and an interpreter. When the JIT hits some new bytecode that it hasn't seen before, it saves the machine code. Later, when it hits the same code, it just reuses the previous machine code that it already generated. Here’s a handy figure for how this works (using Java as an example):
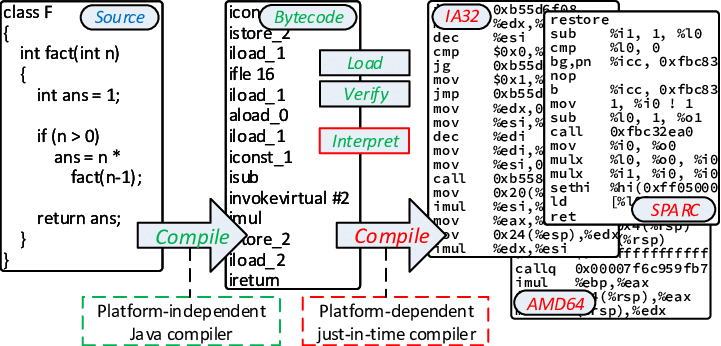
Now, for the most part, bytecode doesn't really change. A single bytecode instruction maps to a set of machine code in almost the same way every time. In fact, everything is exactly the same except for the unique values being passed in as arguments to the machine code instructions. If I have a bit of code that adds two numbers, I need to actually pass in the two numbers, and the bytecode translation needs to account for that, and the machine code translation also needs to account for that. Those two numbers can be anything, we don't know them ahead of time. So we have to incur the compilation cost at runtime, and that means the JIT is pretty slow, at least as slow as our usual interpreter.
But, like, 95% of the compilation is exactly the same from time to time.
Say I had a sentence in English with a variable in it, like MY NAME IS X. And I wanted to translate it to Spanish, MI LLAMO X. And say I had to do this translation 10000 times. It would be kinda silly to have to translate the "MY NAME" part every single time, right? At some point I would just start copy pasting, instead of looking each word up in the Spanish-to-English dictionary? It's always going to be the same, we really only need to slot in whatever value for X.
What's so smart about this particular Python JIT is that it packages templates for all the bytecode instructions. Each bytecode maps to a set of machine code with holes in it. During runtime, the holes get filled up by whatever variables we need. This effectively means that during runtime we no longer have to do the extra step of mapping each bytecode to all the different machine code instructions.
Early benchmarks suggest this change will make Python ~10% faster across the board, though on some systems it's up to ~50% faster. As a regular python user, I gotta say: not a bad Christmas gift!
Everyone's getting laid off
Speaking of Christmas gifts.
No one wants to lay people off during the holidays. But sometimes you do in fact need to fire a bunch of people. The obvious solution? Lay people off in January. So far layoffs have hit Google, Amazon, Discord. I'm seeing numbers like 1 in 3 or 1 in 4 engineers (don't quote me).
There's a lot of ways to read these layoffs.
One way is that this is a market correction. During the covid zero interest era, companies were growing like crazy. Google (disclosure: my previous workplace) hired ~60000 people (!!!) from 2020 - 2022, a 33% increase. Well, it ain't covid anymore. Interest rates are high, money is expensive. Layoffs started in 2023, and this is just a continuation. (And many if not all of these companies are still net up on total employee count, even when accounting for the layoffs)
Another way to read it is that this is a tax fuck up, thanks Congress. Changes to Section 174 of the US tax code went into effect in 2024. The short version is, in 2023 software engineer salaries were tax deductible. In 2024, only 20% of the salary is (the total is amortized over 5 years, 20% at a time). From what I can tell, everyone expected that this tax change wouldn't actually pass, that Congress would block it or revise it before it hit the books. Accountants everywhere were advising clients not to worry about it. Whoops. Lots of companies got hit with a much bigger tax bill than they expected (Microsoft paid ~$5B more this year!), and that money has to come from somewhere. Startups in particular are being hit pretty hard by this one.
A third way to read this is, actually, a lot of employees just weren't that necessary. X neè Twitter did steep layoffs — almost 80% of the company. And though a lot of "thought leaders" predicted instant death, X is still alive and shipping features. The Pareto principle is a harsh but accurate mistress. If you're a CFO at any other silicon valley company, you're probably eyeing your own employee rolls with X in mind. (Doesn't help that there were a ton of folks bragging about how little work they were doing on TikTok. Come on guys, don't give the Boomers more ammo)
All in all, not a fun time to be an intro computer scientist.
I'm sorry, but I cannot fulfill this request - Brown
Imagine you're a tech company, and you're in the business of collecting data from one place and showing it in another place for a price. Maybe you're connecting buyers and sellers, maybe you're indexing links for a search engine, maybe you're sharing social media posts. It doesn't really matter. The main thing is, you're moving information around, and you're collecting some kind of margin.
For the sake of example, let's say you have a dog social media website. People post pictures of dogs, and your algorithm shows those dogs to lots of people. Other companies bid for ad space around the dog photos, and the original poster gets some of the ad revenue back.

At first, things are great. You have a small niche of real people who post dog photos, and presumably some other set of real people who see those photos (and some ads). Some people get paid, and you get paid, and presumably advertisers get some clicks and also get paid, and everyone is happy.
Overtime, though, things get…worse. People start automatically gaming your site, either by faking views, faking ads, or faking posts. Money gets sent out to bad actors. Eventually, the original users and advertisers leave the platform; all that remains is a hive of robots trying to use your system to steal money. Probably none of them care about dogs at all!
Every tech company that's even sorta successful ends up running head first into what I call GMFY users — got mine, fuck you. These people don't care about the platform, or the community, or cute photos of pets. They've found a way to get a quick buck, and they'll pursue it till your platform is dead. If you become successful enough, people build entire careers off fucking with your platform — for example, SEO roles are basically just white-washed spam engineering.
This is an incentives problem. By paying out for views or content, you incentivize people who care about dogs to post their dog photos and build an active community of dog lovers, which is great. But you also incentivize people who don't give two shits about dogs or the dog community and just want money. This dichotomy will always exist, it's inherent to humanity. The best a tech company can do is find ways to make it hard to be a bad actor. That means spending money on teams of engineers that build out anti-spam, anti-abuse technology2.
How do you prevent spam? Well, machines generally behave differently from humans. A machine that automatically clicks on links will have different behavioral characteristics that you can track — it may react faster than a human could at a captcha, or only move in straight lines, and so on. And a machine that automatically posts fake content using, like, Markov chains, probably won't be that coherent — that's why you get websites of literally word vomit.
For a while, it was pretty safe to assume that long form content written in coherent English was written by a real person. Well…

I mean, the jokes just write themselves, don't they?
Amazon is being flooded by…not fake per-se, but at least dubious listings. And while the ones above are pretty funny, those are bottom of the barrel3. A slightly more sophisticated bad actor — ie someone who at least double checks the title, the bar is pretty fucking low — is going to be much harder to track. Which, you know, may not bode well for the rest of us.
Note that I’ve spoken about some of this before, in my post on LLMs as Programming Languages. In that post, I made the claim that LLMs are compilers for English.
This is partially why it's so hard to unseat Google. Every other search index that gets mildly popular suddenly gets slammed with bots and SEO bullshit. Google had literal thousands of engineers working to combat spam across all of its systems!
Note that there's nothing inherently wrong with using GPT to write product descriptions. Folks who make furniture may not be great at marketing copy, using AI is better for them and for the consumer. But leaving OpenAI error messages reeks of automated, spammy behavior.