


Ilya's 30 Papers to Carmack: Relational Networks

This post is part of a series of paper reviews, covering the ~30 papers Ilya Sutskever sent to John Carmack to learn about AI. To see the rest of the reviews, go here.
Paper 17: A simple neural network module for relational reasoning
High Level
One ongoing debate in AI is whether symbolic reasoning is necessary for general intelligence, or is it possible to get by using just statistical methods. In 2025 this debate seems…more conclusively solved. It turns out that, yes, statistical analysis alone can get you pretty damn far, maybe even all the way to AGI. But in 2017, this was not clear at all. Folks on the symbolic reasoning side of the argument would argue — quite compellingly — that neural networks cannot really reason about relationships. They are just, after all, bundles of statistical pattern matching. They do not have the ability to think in symbols and how those symbols relate to each other (at least, not without seeing a million examples first). The ability to do 'zero shot' or 'few shot' learning is a pretty important thing for AGI, and in 2017 it seemed like neural networks would really struggle in real world settings that were "data-poor", "characterized by sparse but complex relations".1
The authors of this paper want to answer the question: can you build a neural network architecture that is better at learning about relationships directly?
To help ground all this, imagine we had a picture of a bunch of different balls and cubes and so on.

A human can look at the image and answer questions like "which shape is the highest up?" or "what shape is under the cylinder?" Most neural nets are terrible at answering questions like this, even today. And yet this sort of reasoning is obviously critical for general intelligence.
To try and solve these kinds of questions, the authors propose a new model called the Relational Network. The core of the RN is a neural network, g, that learns a general function over pairwise relationships, conditioned on some question. So if I have three objects A, B, C, and some question Q, g(A, B, Q) will contain all of the information necessary to represent the relationship between A and B to answer Q.2 For a given Q, we run each pairwise set of objects through g — that is, g(A, B, Q), g(B, C, Q), and g(A, C, Q) — collect the relevant vectors, and then sum them to get a single output vector.3 This vector is then processed by a standard feed forward layer to get a final output.
One problem with the above: what is an "object" in this setting? In the real world there are discrete things with physical properties that we intuitively understand as different things. But a model is just getting a bunch of pixels, or a stack of sentences. If I feed in an image, for eg. how does the model "know" what to care about?4
As with all things in deep learning, the answer is embeddings! Specifically, the authors use other models to generate vector representations of "objects". If the input is sentences, they use an LSTM to run over each sentence and take the last output as a representation of the whole sentence. If the input is images, they use a CNN to get vector representations of each patch. These input processing models can be frozen (ie generic models that are taken off the shelf) or trained jointly with the RN.5
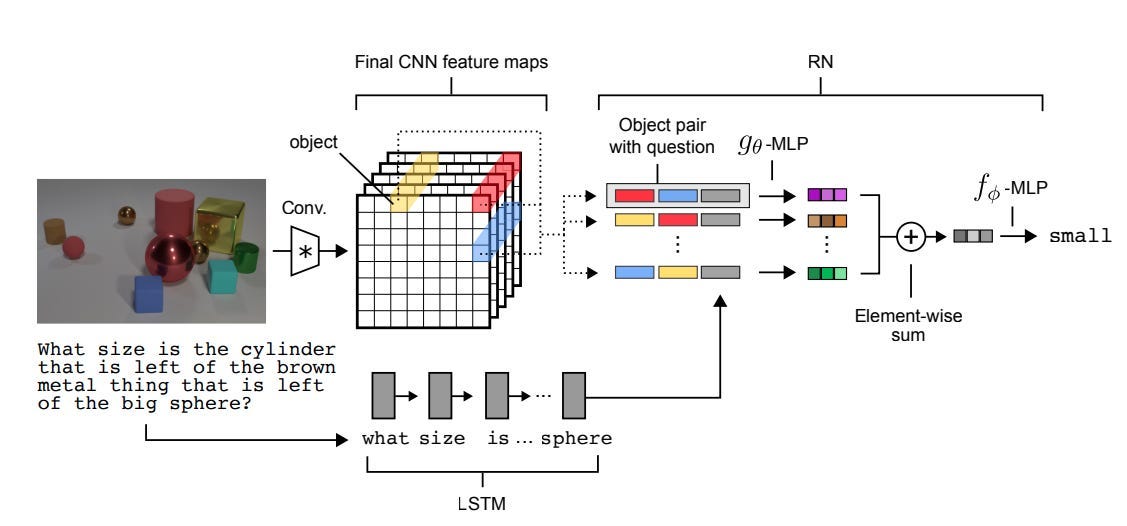
As usual, the authors run their model on a suite of tests where it outperforms baselines, for example on visual QA tasks where the model looks at a picture and has to answer questions about it. I'm normally pretty blasé about the benchmarking done by ML researchers, and that carries over here. But I will mention that the kinds of questions being asked feel much more like general-reasoning than, say, the standard "does this image have a hot dog in it" image segmentation task.
Insights
This is a pretty straightforward representation learning paper — the core of the proposed architecture is manipulating representations in latent space. At each step, the model generates embedding representations of different things, and you can understand the entire model based on what those embeddings actually represent.
You start with some input, which gets parsed out into a set of "object" embeddings. And you create a "question" embedding that represents the underlying task. You take two of the object embeddings and the question embedding and mix them all together to get a "pairwise answer" embedding — that is, a vector that represents how the two objects relate based on the question. And finally you mix all of the "pairwise answer" embeddings together to get an output embedding that represents the final answer.
Like all things in representation learning, none of what I just said makes any sense. These are all just vectors! They're lists of numbers! But the magic of representation learning is that the model learns to operate in vector spaces where those embedding vectors have real, contextually relevant meaning.
To get that "relevant meaning" you have to think in terms of what the model is going to learn. Any neural network can theoretically learn any function, but the architecture of a model will make some functions easier to learn than others.
Consider, for example, the insight that you have to throw a "question embedding" into each pairwise mixing function g. The authors aren't actually sure what g is going to learn — they can't, like, tell you how different input embeddings will result in different outputs. But the authors know that if you don't include a question representation at all, the model will never be able to learn how to modulate the data based on the question being asked. Concretely, if you only put object embeddings into g and then introduce the question embedding after the fact, the output of g would have to contain all of the information about how the two objects relate to each other. This introduces an information bottleneck in the model. Including the question embedding in g itself allows the model to more easily learn how to condition on the question itself.

Another example is the separation of "processing" and "reasoning" in the RN. The authors explicitly carve out a processing module for the input — the CNNs or LSTMs that turn an input image/set of facts into a set of object representations — and a reasoning module that operates on those representations. They could have just fed all the input into a single massive MLP! But a single massive MLP is unlikely to learn a useful function.6 The RN architecture, by comparison, makes it much easier for the model to learn how to solve the task.
I recognize that this is not an easy concept to grasp, and you could write a textbook on the subject. So I'll leave off here by pointing out that this sort of intuition is core to representation learning and model architecture design — you should be breaking down the "steps" you want your model to learn, and then thinking about architectural designs that make it easy to learn those steps.
Last thought.
There's a parallel to self-attention. The pairwise processing that the RN is doing feels very similar to the QKV operation. In some sense, self-attention has a 'baked-in' relational question: "which word in this sentence is most relevant to the word at this index?" You could imagine an RN answering that question for each word successively and getting to an output that looks something like a transformer. Of course, the transformer's implementation is significantly cheaper, and the two aren't 1:1 mathematically equivalent. But still, it's close — you have a pair-wise calculation followed by a sum.
One reason I think this is interesting is because the RN demonstrably works very well on 'concepts'. You can feed in representations of 'facts' that are then used to answer questions about the world. Everything is just a vector, so it's easy to incorporate multimodal data. And in fact, the same applies to transformers. Instead of feeding in a sentence, you could feed in a set of representations about objects, and the transformer would learn how to process those representations and build relationships between them. This is partially why transformers have found success even in spatial or visual domains.
It is still true that neural networks struggle with basic relational reasoning. Try asking an image model for a cheeseburger without cheese. Part of why the ARC challenge is hard is because it depends entirely on learning these kinds of relationships in very sparse settings.
Remember that all of this is happening in embedding space. These relationships are encoded as vectors, and may contain information about everything from relative position to relative color to relative size depending on the task
We've seen this sum/reduce behavior many times before at this point. The sum is necessary for order invariance; that is, we don't want the output of the model to be different if you feed in A before B or vice versa. It would be bad if, for example, the model gave different results to the question "which object is the most blue?" based on the order the data gets fed in.
Implicitly there's a segmentation problem here, which we already discussed as a hard problem to solve!
It's worth noting that the authors play fast and loose with the definition of an "object". If the input was an image of three geometric shapes, we might expect there to be only three "objects" that the model cares about. But in this paper, the authors actually use each patch of the convolutional model output as a separate "object". In other words, the "object" is 'whatever is spatially in the particular patch' instead of any discrete or principled segmentation.
Here “useful” means “solves the task AND generalizes well”.